IT知识

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- 七牛云AI官网入口网址,支持Llama 3、GPT-OSS系列等开源大模型
七牛云推出的AI大模型推理服务,其核心价值在于为开发者与企业提供开箱即用、低成本、高稳定的全栈AI推理能力,无需自建算力集群,无需投入大量精力维护模型环境,即可快速接入各类AI能力,高效实现业务落地。
- PPT超级市场官网入口网址,免费下载PPT模板与PPT作品
PPT超级市场是主打免费、优质、高效、安全的PPT模板资源平台,平台页面整洁美观、操作简洁,同时完成PPT模板搜索页面升级,支持将该页面安装为设备应用,安装后可解锁更多专属功能,进一步提升模板查找与使用效率。

- 北京通用人工智能研究院官网入口网址,非营利性新型研发机构
北京通用人工智能研究院以构建通用智能体为核心目标,致力于研发具备自主感知、认知、决策、学习、执行与社会协作能力,且契合人类情感、伦理与道德观念的通用人工智能技术,推动通用AI从技术研发向实际落地迈进。
- 顺店通零售业务中台官网入口网址,一站式智慧物流等解决方案
顺店通零售业务中台平台服务覆盖零售企业从订单接收、库存调配、发货履约到物流监控的全业务流程,全方位解决线下线上业务割裂、库存管理低效、订单履约慢、物流管控不透明等行业痛点,帮助企业适配数字化零售趋势,提升整体运营效率,打造灵活、智能的零售管理体系。
- 爱短链官网入口网址,企业级在线短链接生成器
爱短链是一款主打高速跳转、安全稳定的企业级在线短链接生成器,聚焦企业级使用需求,支持批量生成、自定义域名,同时搭载高并发访问支撑与防劫持安全机制,兼顾使用效率与链接安全,适配个人分享、企业营销、品牌推广等多场景短链使用需求。
- Wallpaperscraft官网入口网址,高清壁纸资源站免费下载
Wallpaperscraft是一款主打超高清精品壁纸的免费下载网站,站内壁纸均经精心挑选,兼具高分辨率、高清晰度特性,同时覆盖全设备适配尺寸,搭配丰富的分类与精准的筛选功能,操作界面简洁易用,能全方位满足不同用户对美观、个性化壁纸的使用需求。
- 京东内容开放平台官网入口网址,京东打造的内容创作与商业变现平台
京东内容开放平台是京东官方打造的内容创作与商业变现平台,由京东提供技术支持、内容展示等全链路服务,内容创作者可通过平台发布文字、图片、音视频、直播等多形式内容,依托京东生态实现内容带货,赚取相应佣金收益。
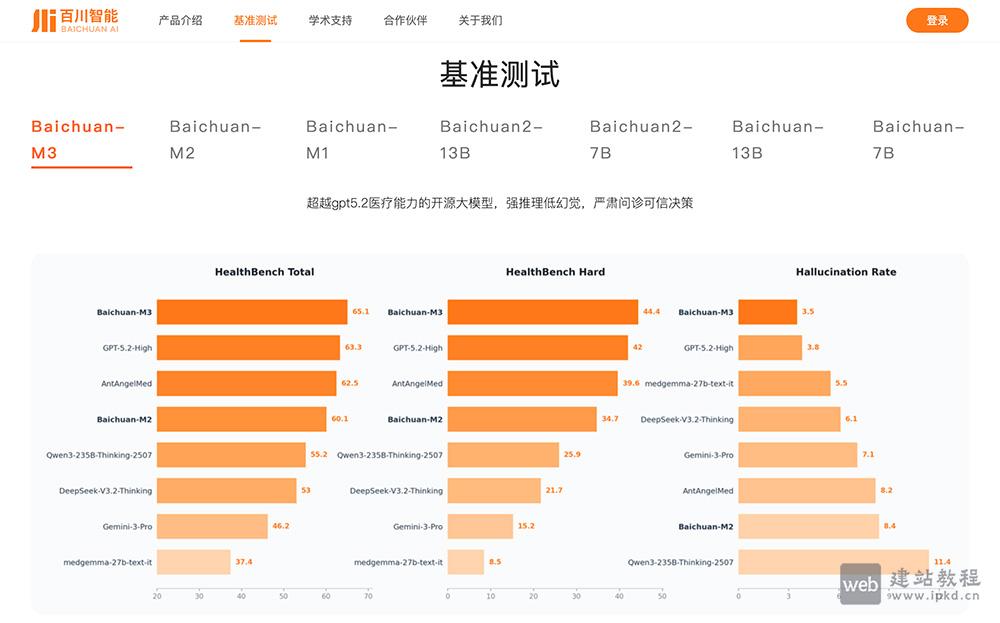
- 百川智能官网入口网址,提供了超千亿参数的大模型
百川智能深耕大模型技术研发与落地,打造了超千亿参数的全系列大模型产品,在多个权威评测中表现优异,中文处理能力超越多款国际知名模型。为用户提供从模型调用、定制开发到行业落地的全链路技术支持,让不同类型用户都能高效利用AI技术提升效率、实现创新。
- 树图思维导图官网入口网址,上传文档自动转换为结构化的导图
树图思维导图是一个基于AIGC的在线思维导图平台。它不仅提供传统的脑图、结构图等可视化功能,还通过AI技术将“一句话需求”或“上传文档”自动转换为结构化的导图。这是传统思维导图与AI技术结合的产物。
- WorkBuddy:腾讯云全场景职场AI智能体桌面工作台,支持一句话下达任务
WorkBuddy是腾讯云推出的面向非技术背景职场人的全场景AI智能体桌面工作台,支持一句话下达任务,可在本地电脑自主规划并完成多步骤复杂办公操作,一站式实现PPT/文档/海报生成、批量数据处理、文件智能整理、本地知识库构建等工作。
- Unreal Engine虚幻引擎官网入口网址,最强大的实时3D创作平台
虚幻引擎搭载全套专业级工具集,助力开发人员高效打造高品质游戏与可视化应用,同时兼顾开发门槛与深度定制需求,既支持无代码可视化开发,也可通过专业编程语言实现高阶优化,是兼顾实用性与专业性的全能型创作引擎。
- 腾讯柠檬清理官网入口网址,腾讯出品的全新Mac清理工具
腾讯柠檬清理是腾讯官方出品的全新Mac系统清理工具,专注于帮助Mac用户高效清理系统冗余文件、优化存储空间,通过智能扫描算法精准定位无用缓存、垃圾文件,一键释放磁盘空间,同时提升Mac系统运行速度,解决电脑卡顿、存储空间不足等痛点,操作简单易上手,兼顾实用性与安全性,适配各类Mac机型。
- Floorplanner在线楼层平面图设计工具,专业级2D和3D楼层平面图
Floorplanner是一款零门槛免费在线设计工具,平台支持实时3D视图预览,让用户直观查看设计方案的最终呈现效果,同时可生成高质量3D渲染图,兼顾实用性与展示性,适配个人、行业从业者等多类用户的设计需求,同时提供付费增值服务,满足高阶使用需求。
- 高德开放平台官网入口网址,中国领先的基于位置的大数据服务平台
高德开放平台旨在为用户提供“地图 + 位置”的全链路服务。它不仅提供传统的地图展示功能,还通过海量的POI(兴趣点)数据、实时路况和高精定位技术,帮助企业构建基于地理位置的智能应用。
- ZenMux:全球首个搭载保险赔付机制的企业级AI大模型聚合平台
ZenMux平台采用OpenAI与Anthropic双协议兼容设计,内置智能模型路由、自动故障转移、全球边缘加速能力,核心特色为专属「AI保险」——模型出现幻觉、延迟过高或输出质量不达标时自动赔付,同步反馈问题数据助力用户产品优化。