采集
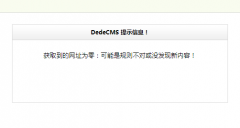
- 获取到的网址为零:可能是规则不对或没发现新内
dedecms网站采集测试节点的时候是正常的,数据都是有的,但是正规采集的时候确提示“获取到的网址为零:可能是规则不对或没发现新内容!” 不知道这个错误怎么出来的,昨天还可以采集的,今天就不能用了,暂时不知道怎么解决

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- 织梦DEDECMS系统如何修复无法自带采集https网站问题
织梦采集是不能完全兼容采集https的目标站的,我们来把它完善使它支持http和https。 现在只需要改动几个文件即可,改动的文件有4个,由于改动地方有好几处,推荐用下载文件覆盖的方式,避免引起不必要的错误。 提示:覆盖之前建议先备份你的
- 帝国CMS7.5版采集功能升级,更灵活
论坛有人反映帝国cms的采集功能有近十年没更新了,所以团队对论坛遇到较多的问题进行整理,在帝国CMS7.5版对采集功能进行部分升级,使采集更灵活。帝国CMS7.5版采集功能升级,更灵活:1、采集替换字符设置 新增支持自定义字段。2、采集广告
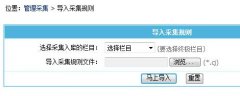
- 帝国CMS7.0功能之新增采集规则导出与导入功能
帝国cms7.0新增采集规则导入与导出功能(导出为*.cj文件),方便转移采集规则与方便用户分享规则。且支持所有系统模型,采集导入与导出可自动识别不同系统模型的字段进行导入与导出操作。 上传以下图片:
- 帝国CMS如何防止你的网站数据被采集
帝国cms如何防止你的网站数据被采集,数据采集,对于个人站长来说是个不错的选择,因为大多个人站长花不起钱去请网站编辑。虽然,没有任何一个软件能想网站编辑那样有效工作,但是只要你用的好,是不会影响的。 今天讨论的是如果让你的网站数据不被别人采
- 帝国CMS之完美解决采集时出现“标题与作者完全
帝国cms之完美解决采集时出现“标题与作者完全一样不采集”的问题,下面我们就来看看这个问题的解决方法。 出现的原因就是当前采集的文章标题和你数据库中已经采集的文章标题重复了,就是说已经采集过了。 这个是正常的,因为你
- 帝国CMS防采集功能使用说明
帝国cms防采集功能使用说明: 1.开启防采集功能:参数设置-》信息设置 2.增加随机防采集字符:插件治理-》防采集随机字符治理(只要字符不能显示出来都可以加。字符越多防采的效果越好) 3.在内容模板需要显示随机字符的地址地方加上:&quo
- 帝国cms如何采集规则加上采集来源地址的方法
帝国cms如何采集规则加上采集来源地址的方法 帝国cms采集规则采集来源地址只需要加在模型里加上一个“empireselfurl”这个字段不用设置正则,入库后他自然就是采集的页面地址
- 织梦cms5.7不能采集分页的解决办法
织梦cms5.7不能采集分页的解决办法,这是是什么原因呢?那是因为程序默认不会采集分页,也就是采集的时候只会采集到指定url的第一页的修改方法。那么我们应该如何修改呢? 打开文件\include\dedecollection.class.p
- 帝国CMS如何解决采集图片只采集URL链接
在采集文章的时候,列表页和内容页的url都是正确列示的,但是内容采集到的只显示图片的rul,那么应该如何解决采集图片只采集url链接问题呢? 内容源码: <script type="text/javascript"
- 织梦cms栏目与文档如何自动获取相关关键词
发布文章特别是采集发布时,一般不能采集到准确和热门的相关关键字,但是如果自动获取相关关键词的也是可以的,我们现在来看看它是如何实现的。
- 帝国cms采集规则加上empireselfurl
帝国cms采集规则加上empireselfurl 帝国cms采集规则采集来源地址只需要加在模型里加上一个“empireselfurl”,这个字段不用设置正则,入库后它就是采集页面的地址。