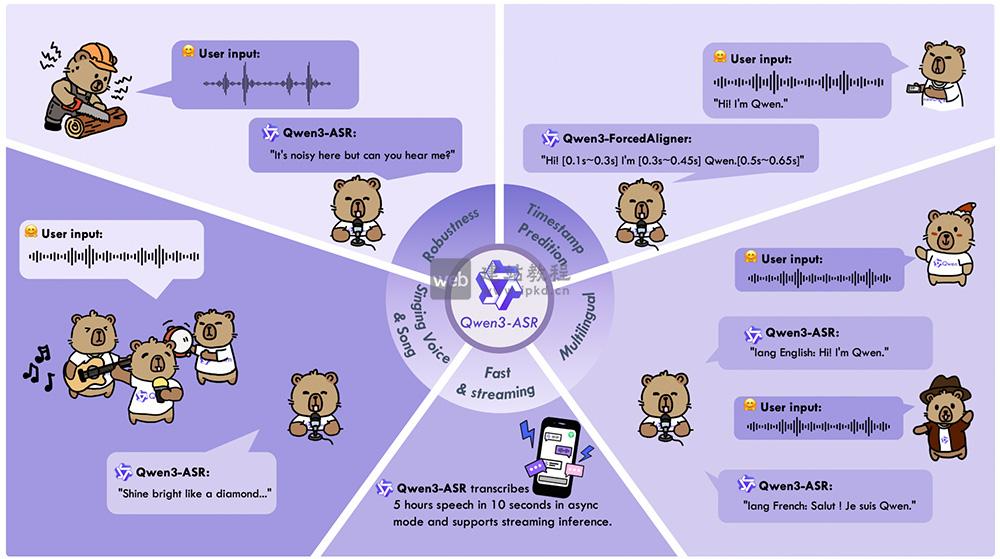
帝国cms技巧之完美解决分页采集正则及过滤问题,下面我们看看修改方法:
从文章的源代码中获得的
第一种:
<p align='center'><b><font color='red'>[1]</font> <a href='/Eat/RMenu/200806/38611_2.html'>[2]</a> <a href='/Eat/RMenu/200806/38611_3.html'>[3]</a> <a href='/Eat/RMenu/200806/38611_4.html'>[4]</a> <a href='/Eat/RMenu/200806/38611_2.html'>下一页</a> </b></p>
编写的规则:
选全部列出式
区域正则:
<p align='center'><b><font color='red'>[!–smallpageallzz–]'>下一页
链接正则:
<a href='[!–pageallzz–]'>
第二种
采集代码
<p align='center'><b><font color='red'>[1]</font> <a href='/lw/3/lw_31205_2.html'>[2]</a> <a href='/lw/3/lw_31205_2.html'>下一页</a> </b></p> <center>《
编写的规则:
选用上下导航式:
分页区域正则:<font color='red'>[!–smallpagezz–]下一页
分页链接正则:<a href='[!–pagezz–]'
新闻正文正则:
src="http://pagead2.googlesyndication.com/pagead/show_ads.js">
</script></td>
</tr>
</table>[!–newstext–]</td>
</tr>
<tr>
<td width=5></td>
过滤广告正则:
</p> <center>[!–ad–]</center>,</p><p align='center'>[!–ad–]</b>
例如:http://www.3edu.net/lw/3/lw_31205.html
第三种
<p align="center"><img src="/bgy/Images_1/sy8.gif" border="0" align="absbottom"> <FONT style="COLOR: #ff0000">【1】</font> <a class=page href="094221656-2.html" target=_self>【2】</a> <a class=page href="094221656-3.html" target=_self>【3】</a> <a class=page href="094221656-4.html" target=_self>【4】</a> <a class=page href="094221656-5.html" target=_self>【5】</a> <a href="094221656-2.html"><img src="/gwy/Images1/xy.gif" border="0" align="absbottom"></a></p>
编写的规则:
"全部列出"式正则设置:
分页区域正则(无)
分页链接正则: <a class=page href="[!–pageallzz–]" target=_self>
第四种:
<DIV class=pageContainer> <DIV class=pager><span class="nextprev"><< 前一页</span><span class="current">1</span><a href="0731_3493_686224_1.shtml" title="转到第2页">2</a><a href="0731_3493_686224_2.shtml" title="转到第3页">3</a><a href="0731_3493_686224_1.shtml" class="nextprev" title="后一页">后一页 >></a></DIV></DIV></DIV>
</div>
选全部列出式
区域正则:
<DIV class=pageContainer> <DIV class=pager><span class="nextprev">[!–smallpageallzz–]" class="nextprev" title="后一页">
链接正则:
<a href="[!–pageallzz–]"
上面是“帝国cms技巧之完美解决分页采集正则及过滤问题”的全面内容,想了解更多关于 帝国cms 内容,请继续关注web建站教程。
当前网址:https://ipkd.cn/webs_1156.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!