盘古大模型5.5是华为在开发者大会2025上发布的最新一代人工智能大模型,强调“不作诗,只做事”,专注于解决实际产业问题,推动千行百业的智能化升级。
盘古大模型5.5功能特点:
1、自然语言处理(NLP):
– 高效长序列处理:通过 Adaptive SWA 和 ESA 技术,能够轻松应对 100 万 token 长度的上下文。
– 低幻觉:采用知识边界判定和结构化思考验证等创新方案,提升模型推理的准确度。
– 快慢思考融合:自适应快慢思考合一技术,根据问题难易程度自动切换思考模式,简单问题快速回复,复杂问题深度思考,推理效率提升 8 倍。
– 深度研究能力:盘古 DeepDiver 通过长链难题合成和渐进式奖励机制,在网页搜索、常识性问答等应用中表现出色,可在 5 分钟内完成超过 10 跳的复杂问答,并生成万字以上专业调研报告。
2、多模态:
世界模型:为智能驾驶、具身智能机器人训练构建数字物理空间,实现持续优化迭代。例如在智能驾驶领域,可生成大量训练数据,无需依赖高成本路采。
3、预测:
Triplet Transformer 架构:将不同行业的数据进行统一的三元组编码和预训练,提升预测精度和跨行业、跨场景的泛化性。
4、科学计算:
AI 集合预报:例如深圳气象局基于盘古大模型升级的“智霁”大模型,首次实现 AI 集合预报,能更直观地反映天气系统的演变可能性。
5、计算机视觉(CV):
300 亿参数视觉大模型:支持多维度泛视觉感知、分析和决策,构建工业场景稀缺的泛视觉故障样本库,提升业务场景的可识别种类与精度。
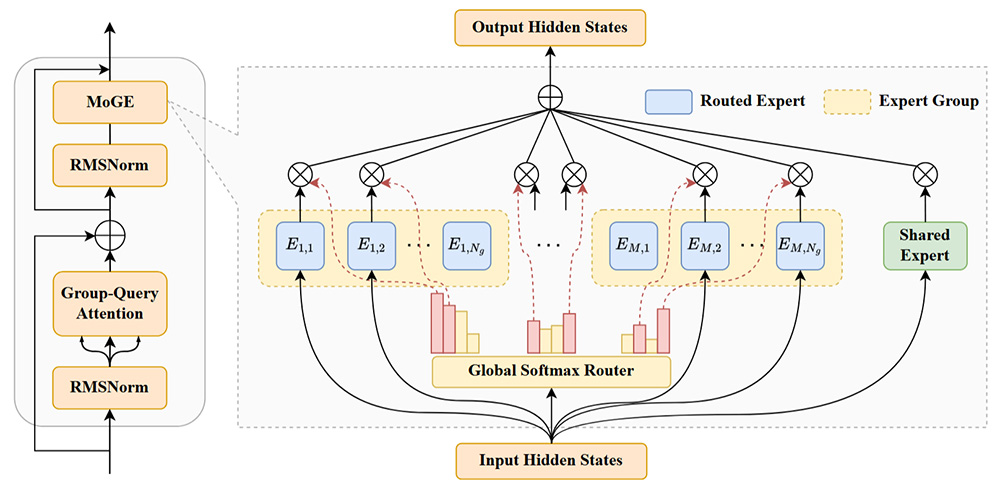
6、盘古 Ultra MoE:
– 超大规模与稀疏激活:拥有 7180 亿参数,采用 256 个路由专家,每个 token 激活 8 个专家,激活量为 39 亿,具备超大规模和高稀疏比的特性。
– 先进架构设计:引入 MLA(Multi-head Latent Attention)注意力机制,有效压缩 KV Cache 空间,缓解推理阶段的内存带宽瓶颈。
– 稳定训练技术:提出 Depth-Scaled Sandwich-Norm(DSSN)稳定架构和 TinyInit 小初始化方法,解决了超大规模 MoE 模型训练过程中的稳定性难题。
– 高效负载优化:采用 EP group loss 负载优化方法,保证各个专家之间保持较好的负载均衡。
相关阅读文章
七牛云AI官网入口网址,支持Llama 3、GPT-OSS系列等开源大模型
DeepSeek-R1-Safe:浙大与华为联合研发的安全专项大模型
PixVerse R1:爱诗科技打造,全球首个通用实时世界模型
上面是“盘古大模型 5.5:一款专注于解决实际产业问题,推动千行百业的智能化升级”的全面内容,想了解更多关于 IT知识 内容,请继续关注web建站教程。
当前网址:https://ipkd.cn/webs_19225.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!













