IT知识

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- Noema Lab创作实验室:为不同阶段的音乐创作者提供一站式智能工具
用户只需输入主题关键词,即可借助AI生成结构完整、韵律优美的专业歌词,支持中文、英文、粤语等多语言创作,还能自定义风格、情感与主题方向;同时搭载故事歌词创作功能,可将完整故事转化为符合音乐韵律的歌词文本。
- InsMelo官网:一款AI歌曲创作平台,提供400多种音乐风格
InsMelo平台支持歌词、文本、图像三种输入形式转化为音乐,涵盖400+种音乐风格,且生成的所有音乐均为免版税版权,可自由用于个人分享或商业投放。
- Genve AI:一款AI视频翻译工具,专业配音与口型同步
Genve AI是一款基于浏览器的一站式多媒体AI工具,核心功能为视频翻译配音+AI口型同步,无需下载安装即可使用。它依托先进的神经网络技术,自动完成视频语音转录、多语言翻译、原声克隆,最终实现配音与口型的精准匹配,帮助用户打破语言壁垒,轻松推动内容全球化传播。

- ArchRender官网:一款专为建筑师与设计师打造的AI渲染工具
ArchRender是一款专为建筑师与设计师打造的AI驱动渲染工具,核心价值在于大幅简化渲染流程、提升产出效率,无需复杂的灯光调试与场景搭建,就能快速生成逼真的摄影级视觉效果。

- Nereo:全球首款支持单提示词生成完整60秒动漫短片的AI工具
工具依托Sora 2、Veo 3、Seedance等行业领先AI模型研发,支持多平台视频比例适配,新用户可享免费试用额度,升级付费套餐可解锁更多生成次数与优先处理服务,定位为面向全圈层创作者的便捷动漫短片创作平台。
- PhotoGPT:一键完成图像生成、编辑与优化,输出无水印超高清内容
工具操作零门槛,无需专业摄影技巧与技术经验,支持一键完成图像生成、编辑与优化,输出无水印超高清内容,广泛适配肖像创作、产品摄影、社交营销素材制作等多元场景,为不同需求用户提供高效的视觉内容解决方案。

- NineFengShui:传统五行八卦理论与现代AI技术的家居风水分析工具
工具无需上传详细户型图,操作零门槛,同时结合生肖分析与AI跟进指导,覆盖从基础风水评估到深度布局优化的全需求,定位为全球房主、室内设计师及风水专家的实用辅助工具。
- Talking Pet AI:将用户上传的宠物照片转化为会说话的高清视频
Talking Pet AI是一款趣味十足的AI在线工具,核心功能是将用户上传的宠物照片转化为会说话的高清视频,凭借自然的唇形同步与逼真表情效果,为用户打造新颖的情感表达与社交分享载体。
- Voor AI:一款功能全面的先进AI图像与视频生成工具
Voor AI提供丰富的流行AI图像效果与视频模板,覆盖浪漫、动作、复古、科技等多种风格,助力用户轻松制作出具有高吸引力与传播力的内容,快速打造病毒式爆款作品。
- Soolo AI:面向独立创业者、小企业及创意工作室的AI品牌建设工具
Soolo AI是一款面向独立创业者、小企业及创意工作室的AI驱动一站式品牌建设工具,从品牌名称、标志设计到广告制作、战略规划,用户无需专业技能即可在几分钟内完成品牌从0到1的搭建,大幅降低品牌建设的时间与资金成本。
- Mintshot.ai:一款将用户自拍转化为专业证件照的AI在线工具
Mintshot是一款由Lowside Labs Inc开发的AI驱动在线证件照制作工具,核心价值在于帮助用户将普通自拍快速转化为高质量专业证件照,提供便捷、高效且高性价比的证件照解决方案。
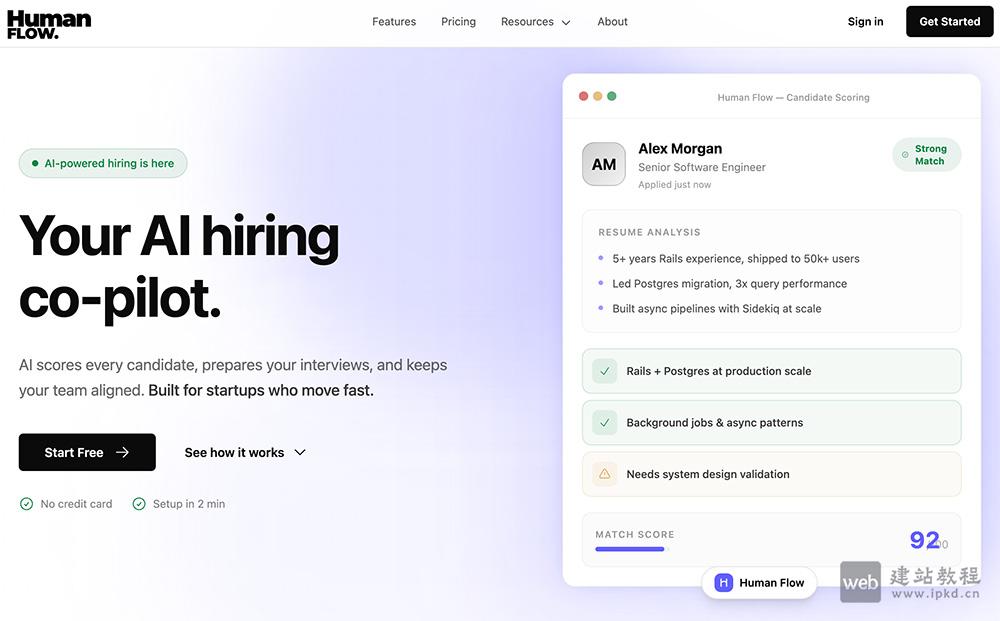
- Human Flow:一款专为初创公司和成长型团队打造的AI招聘平台
Human Flow是一款专为初创公司与成长型团队打造的AI驱动招聘平台,核心定位是通过智能化技术简化招聘全流程、提升招聘效率,精准解决中小团队招聘资源有限、流程繁琐、协同低效等痛点。

- ChartinAI:一款零编程、零设计的高效智能AI图表生成工具
ChartinAI是一款高效智能的AI图表生成工具,用户仅需输入一句话描述需求,工具即可在数秒内输出多套图表方案,支持12种主流图表类型与9种设计风格,兼容本地数据上传与在线数据调取,生成的图表支持高清格式导出,全方位满足工作汇报、学术研究、自媒体创作等多场景的数据可视化需求。
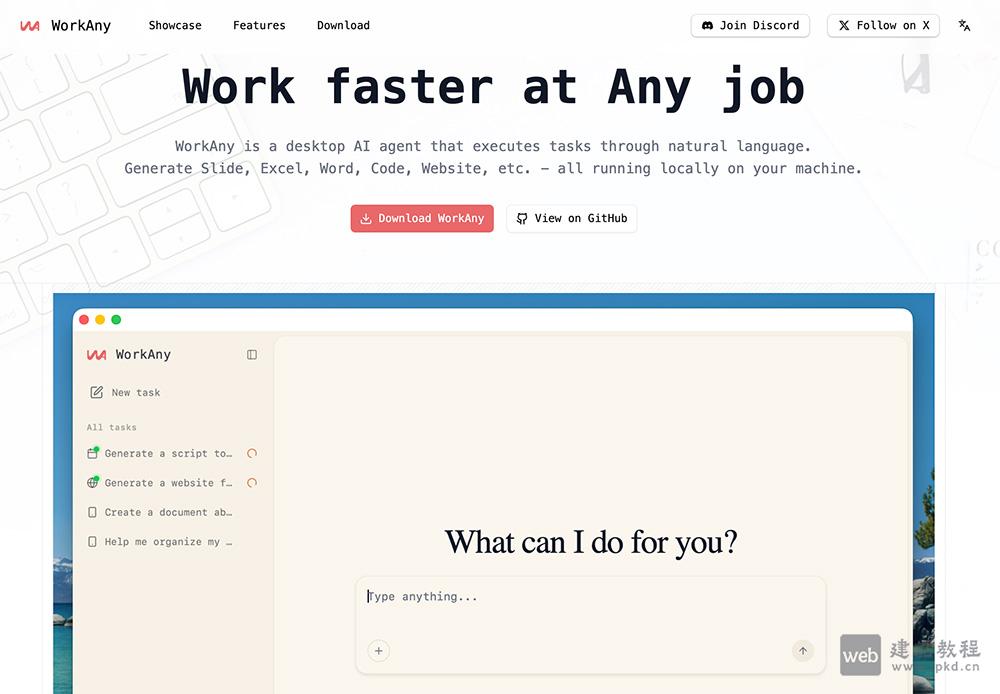
- WorkAny官网:一款支持本地运行的开源AI桌面智能体
WorkAny是一款支持本地运行的开源AI桌面智能体,该工具能在本地快速生成幻灯片、Excel、Word、代码、网站等多元内容,大幅提升工作效率;同时采用沙箱技术保障代码执行安全,支持多AI模型适配与外部工具灵活扩展,是助力各场景生产力提升的高效工具。
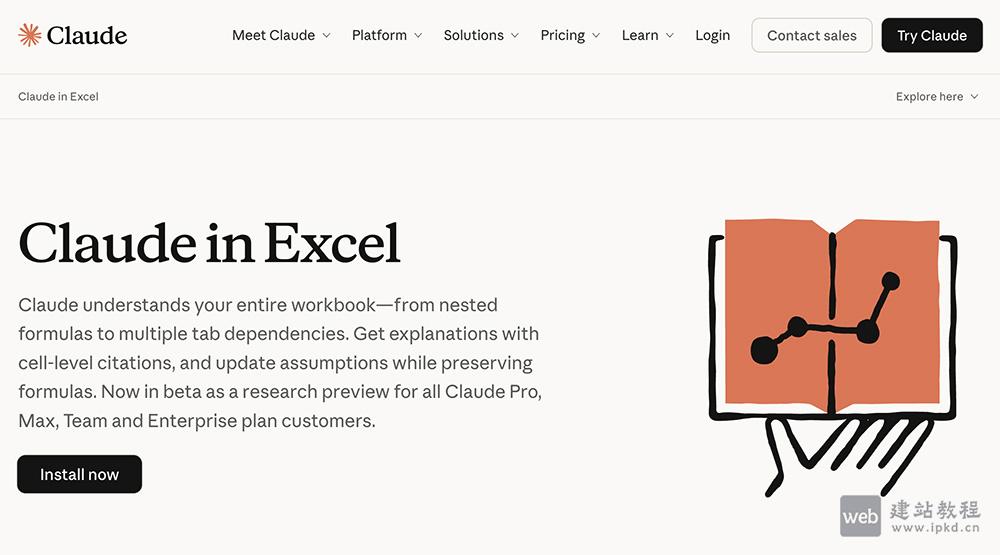
- Excel Claude:一个重构用户与Excel交互模式的AI Excel处理工具
Excel Claude大幅降低专业Excel技能门槛,提升数据处理效率与智能化水平,是企业与个人数据处理分析的核心辅助工具。目前工具处于测试阶段,作为研究预览版向Claude Pro、Max、团队及企业计划用户开放。