AI开源项目
- Ultralytics官网:一个轻量化开源计算机视觉与AI深度学习框架
Ultralytics是一款易用性极强的开源计算机视觉(CV)与深度学习框架,框架覆盖从数据准备到模型部署的全流程,兼具“高性能、易上手、多端适配”三大核心优势,广泛应用于工业、安防、智能驾驶等多领域场景。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
- FastBuildAI:一款面向AI开发者、创业者开源零代码AI应用开发框架
FastBuildAI是一款面向AI开发者、创业者及AI兴趣群体的开源AI应用开发框架,通过可视化零代码界面,无需专业编程技能,几分钟即可完成部署并搭建出包含营销、计费、支付功能的完整AI应用,彻底降低AI应用开发门槛。

- UniVG:百度团队研发的AI视频生成系统,支持文本、图像组合输入
UniVG是百度团队研发的多条件驱动统一AI视频生成系统,核心突破在于支持文本、图像的任意组合输入,可灵活适配不同自由度的视频生成需求,有效解决传统视频生成模型仅能处理单一任务、单一输入的局限性。
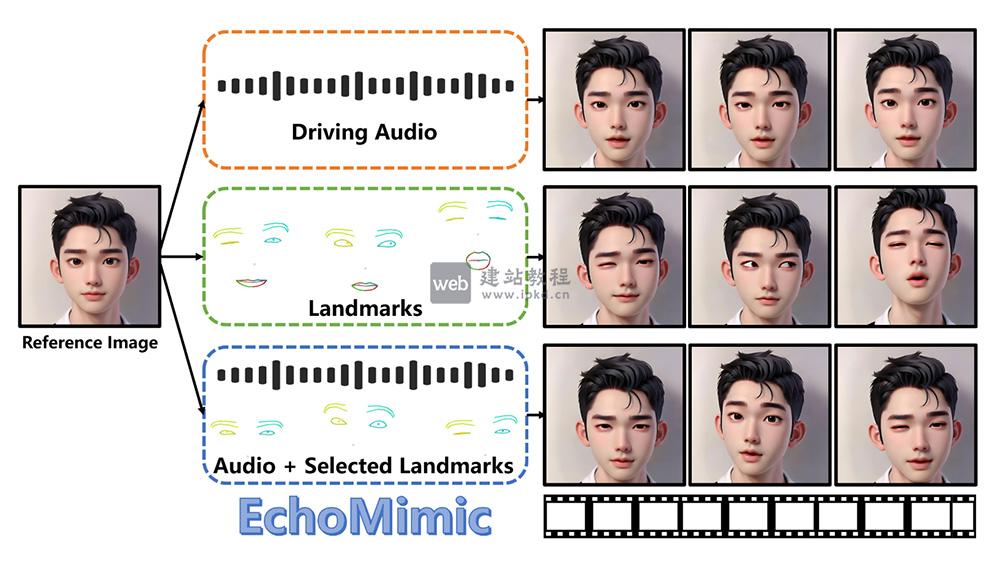
- EchoMimic:蚂蚁集团支付宝研发的高精度肖像动画生成工具
EchoMimic可将静态人像转化为表情丰富、动作流畅的动态视频。相较于SadTalker、MuseTalk等同类型工具,EchoMimic在动画自然度与细节可控性上实现显著突破,适用于虚拟主播、视频编辑、数字人交互等多元场景。
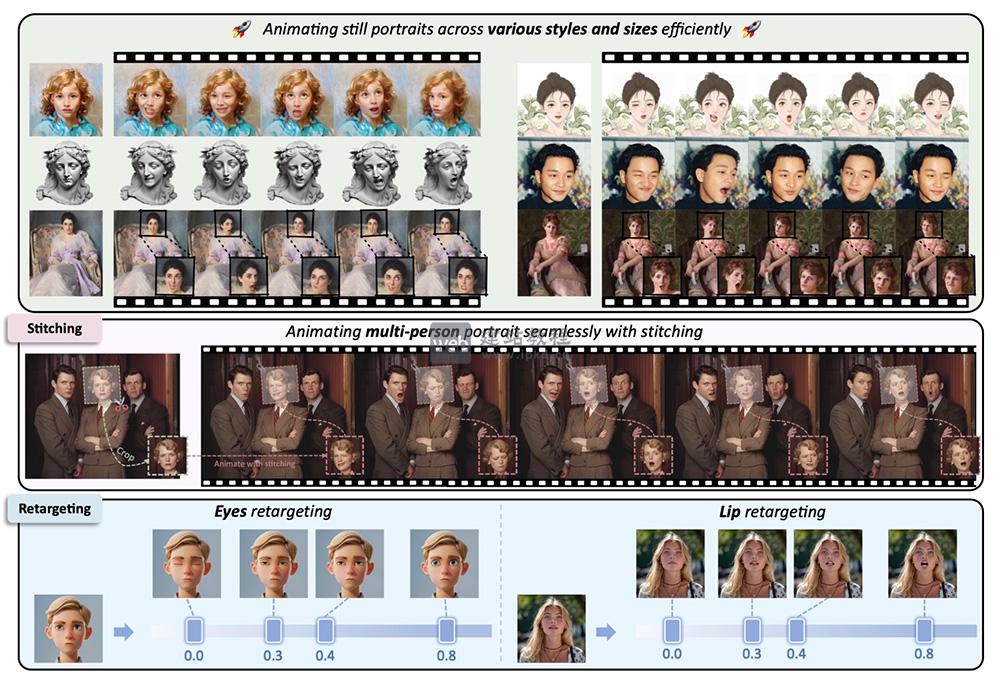
- LivePortrait:快手科技与复旦大学联合开发的开源AI肖像动画技术框架
LivePortrait核心能力是将静态人像照片转化为具备逼真面部表情与动作的动态视频,同时支持通过视频或摄像头驱动的动作迁移,为数字内容创作提供高效、可控的人像动画解决方案。

- DUIX:硅基智能开源的2D真人级AIGC实时渲染数字人交互平台
DUIX是硅基智能开源的2D真人级AIGC实时渲染数字人交互平台,旨在为开发者提供低成本、高灵活性的数字人Agent开发能力。开发者可基于该平台快速接入多模态能力,实现数字人实时交互,并一键部署至多终端,赋能各行业智能化交互场景。

- Wiseflow:一款开源免费、轻量化敏捷的信息挖掘工具
Wiseflow是一款开源免费、轻量化敏捷的信息挖掘工具,支持从网站、微信公众号、社交平台等多类信息源中,按用户预设关注点精准提炼核心讯息,自动完成标签归类并同步至数据库。
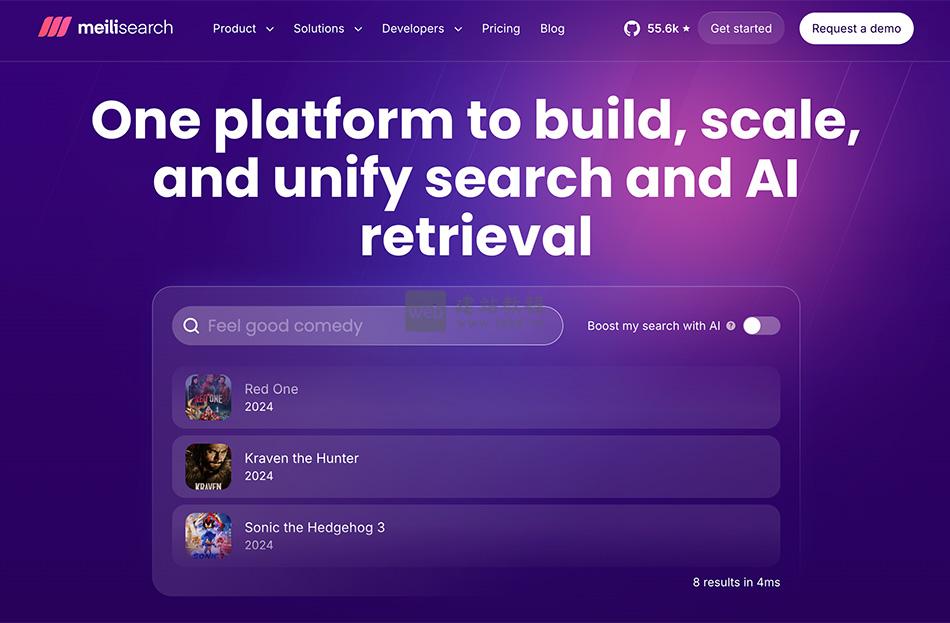
- Meilisearch官网:一款轻量级、高性能的开源搜索引擎
Meilisearch是一款轻量级、高性能的开源搜索引擎,可无缝集成至各类应用程序、网站及工作流程,助力开发者快速构建高效、友好的搜索体验,提供丰富的开箱即用功能,大幅简化搜索功能的开发与部署流程。
- AutoStudio官网:一款支持多轮对话式交互的图像序列生成工具
AutoStudio是一款支持轮对话式交互的图像序列生成工具,核心能力是在用户持续添加、修改指令的过程中,始终保持生成图像的主题、风格与元素一致性,可直接产出情节连贯、分镜完整的漫画与故事板内容。
- ClotheDreamer:由上海大学、腾讯优图实验室等联合研发的3D虚拟试穿技术系统
ClotheDreamer通过自然语言与3D建模的高效衔接,显著降低了3D服装设计的技术门槛,为时装设计师、3D艺术家、虚拟服饰开发者提供了直观、高效的创作工具,在时尚设计、元宇宙服饰、虚拟试穿等领域具备广阔的应用前景。

- MimicMotion:腾讯与上交大联合研发的可控式高质量视频生成框架
MimicMotion是由腾讯与上海交通大学联合研发的可控式高质量视频生成框架,支持生成任意时长、动作精准可控的视频内容,可高效产出细节丰富、逼真度高的人类动作视频,同时实现对动作、姿态、视频风格的精细化调控。
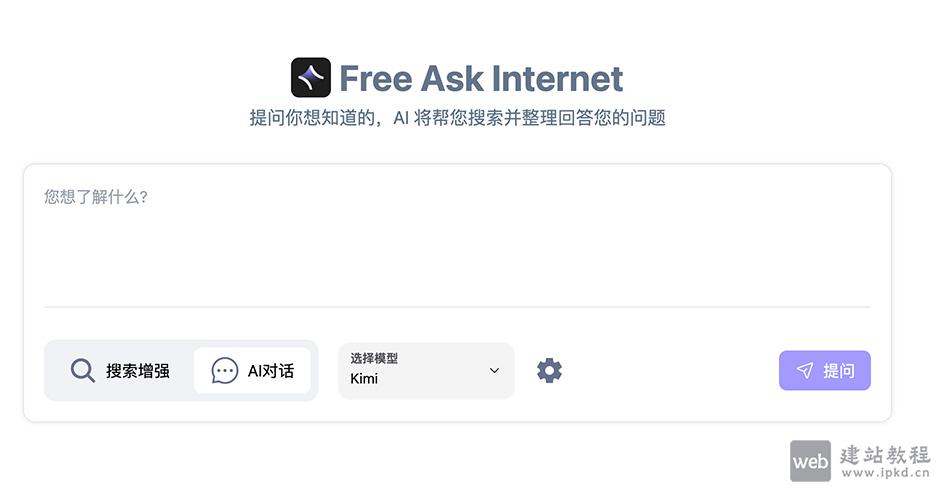
- FreeAskInternet:免费、私有化、本地化运行的搜索聚合与AI问答工具
FreeAskInternet工具通过集成SearXNG多引擎搜索器,聚合全网信息后,交由ChatGPT 3.5、Qwen、Kimi、智谱AI(GLM)等模型进行内容整合与回答生成,全流程本地闭环运行,兼顾信息获取效率与数据安全。
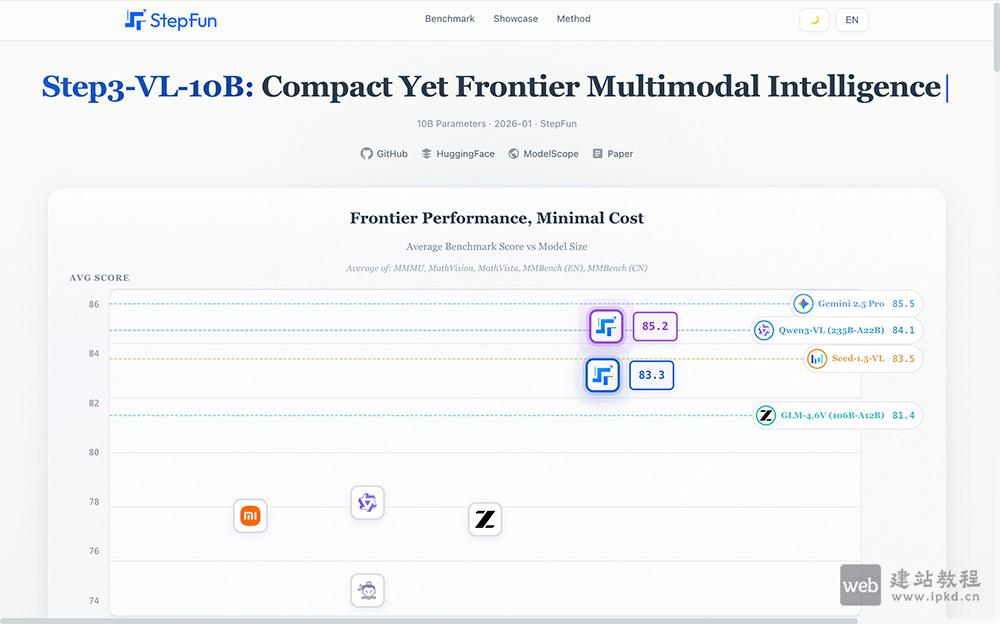
- Step3-VL-10B:10B参数开源多模态模型,以轻量架构比肩200B级性能
Step3-VL-10B是阶跃星辰推出的轻量级开源多模态模型,仅搭载10B参数,却能在视觉感知、逻辑推理、数学竞赛及通用对话等核心任务中,达到200B大参数模型的性能水准。

- TryOnDiffusion:谷歌推出的一项高保真虚拟试衣技术
TryOnDiffusion是一款基于双UNet扩散架构的虚拟试衣AI模型,核心能力是生成服装穿在目标人物身上的高逼真可视化效果。它能够在精准保留服装细节纹理的同时,自适应人物的显著身体姿势与体型变化,在定性与定量评测中均达到业界领先水平,是高效解决虚拟试衣场景痛点的技术方案。

- DeepFaceLab:高逼真换脸工具,中文本地化适配降低使用门槛
DeepFaceLab是一款基于深度学习的人脸交换工具,能精准识别并替换图片、视频中的人脸,生成高度逼真自然的换脸内容。在同类换脸软件中,它以安装最简单、使用最便捷、更新迭代最快的核心优势,成为众多用户的首选工具。