AI开源项目

- TextBase:极简AI聊天机器人开发框架,快速搭建可定制化对话应用
TextBase是一款专为AI聊天机器人开发设计的轻量级Python框架,核心优势在于极简易用、高度可扩展,能帮助开发者快速搭建、迭代和优化聊天机器人,是从入门到生产级聊天机器人开发的优选工具。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- FaceChain:一张照片打造专属数字替身的深度学习模型工具
FaceChain是一款聚焦个人数字形象定制的深度学习模型工具,核心优势在于极低的训练门槛——用户仅需提供至少一张个人照片,即可快速生成高度贴合自身特征的专属数字替身,为数字内容创作、虚拟社交等场景提供个性化解决方案。

- EasyPhoto:WebUI插件式AI肖像生成工具,快速定制专属数字分身
EasyPhoto是一款适配WebUI的AI肖像生成插件,核心功能是基于用户上传的肖像照片训练专属数字分身,并通过推理生成个性化AI肖像。它兼顾易用性与灵活性,支持多人生成、多基础模型适配,可在Windows和Linux系统部署,是定制个人数字分身的高效工具。

- DeepFaceLive:开源实时AI换脸工具,高逼真视频合成赋能多领域创新
DeepFaceLive是一款免费开源的实时直播AI换脸工具,基于先进深度学习算法,可实现高度逼真的面部合成效果——将一个人的面部特征精准映射到另一个人的身体视频中,完美还原原面部的表情、动作细节,为影视制作、游戏开发、虚拟现实等领域提供高效创新的技术解决方案。

- CustomNet:三维增强型对象定制生成技术,商品图融合的革新方案
CustomNet是一个在文本到图像生成领域,将自定义对象(如特定商品)自然融入新场景并完整保留其样式、纹理细节,是极具实用价值的核心需求——尤其为商品图融合、创意设计等场景提供了全新可能。

- 易魔声EmotiVoice:开源多情感TTS引擎,2000+音色解锁双语语音合成
易魔声EmotiVoice是一款功能强大的开源TTS引擎,核心亮点在于支持中英文双语合成、覆盖2000+多样化音色,以及行业领先的情感合成能力——可精准生成快乐、兴奋、悲伤、愤怒等多种情绪语音,为语音内容创作注入丰富情感张力。
- InvokeAI:Stable Diffusion 领先创意引擎,开源全能型AI图像生成工具
InvokeAI是一款基于Stable Diffusion模型的开源全能型AI图像生成与处理平台,核心优势在于通过简化的工作流程、丰富的功能扩展与低门槛部署特性,让专业创作者、艺术家与爱好者轻松驾驭AI生成技术。
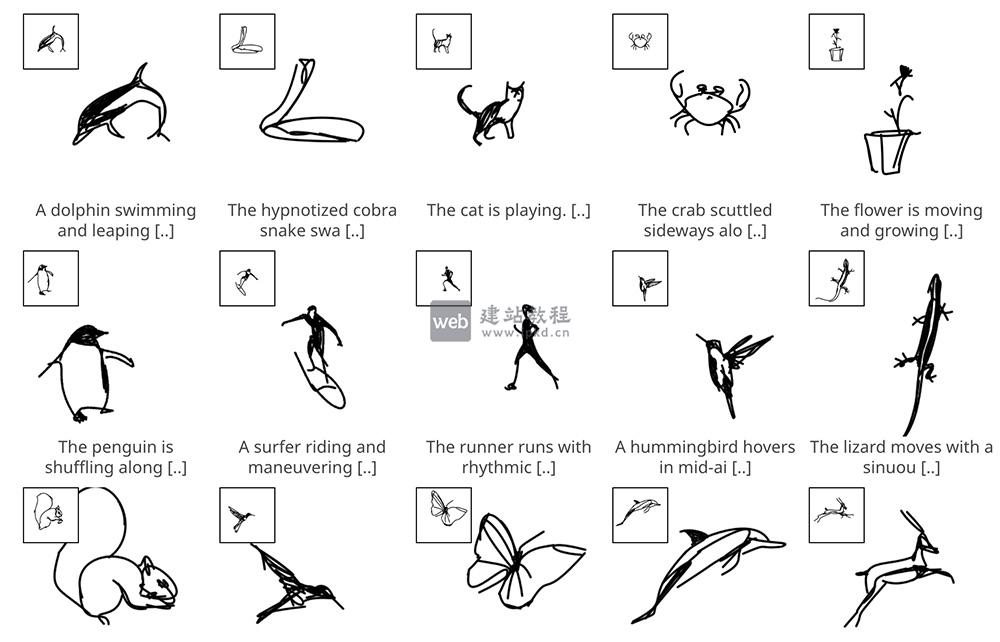
- LiveSketch:文本驱动静态素描动画生成工具,让涂鸦轻松 “活” 起来
LiveSketch是一款聚焦“素描动效化”的AI生成视频工具,它为用户提供了直观、低门槛的创作方式,无需专业动画技能,就能让寥寥几笔的涂鸦或素描赋予生命,广泛适配讲故事、插画展示、网站设计、演示文稿等多元场景,让静态视觉内容更丰富有趣。

- LucidDreamer:无域限制3D场景生成管道,解锁真实世界级场景创作
LucidDreamer是一款一款无域限制的3D场景生成管道,深度借助现有大规模扩散生成模型的强大能力,实现跨领域、高保真的3D场景创作。

- DemoFusion:开源AI图像重绘增强工具,轻松实现16倍+超分与细节焕新
与传统“单纯放大”不同,DemoFusion采用创新的补丁式处理方案:先通过Stable Diffusion等免费开源AI模型生成低分辨率基础图像,再通过专属框架挖掘模型潜力,为图像添加丰富细节并提升分辨率,实现“超分+细节增强”的双重效果,而非简单拉伸像素。

- HandRefiner:精准修正畸形手部的图像后处理方案,无损原图风格与内容
HandRefiner提出一种针对性图像后处理方法,核心目标是在完全保留图像其他部分原貌的前提下,精准修正生成图像中形状异常的手部。
- DreamTalk:清华联合阿里、华中科大研发,音频驱动的高逼真照片说话框架
DreamTalk是由清华大学、阿里巴巴与华中科技大学联合开发的扩散模型驱动面部动画生成框架,核心能力是让静态人物照片“开口说话”,支持匹配歌曲、多语言语音、嘈杂音频等多种声音类型,生成的唇部动作与表情风格高度自然逼真,打破了传统照片说话技术对纯净音频、表情参考的依赖。

- VideoCrafter:腾讯联合高校打造,支持多场景连贯生成的开源视频扩散模型
VideoCrafter基于扩散模型与机器学习技术,支持文本到视频(Text2Video)、图像到视频(Image2Video)两大核心能力,即使是无视频编辑或动画经验的新手,也能轻松制作出媲美专业水准的视频内容。

- Audio2PhotoReal:Meta AI重磅技术,音频直驱超写实全身虚拟人物生成
Audio2PhotoReal生成的虚拟人物不仅视觉质感逼真,更能细腻复刻对话中的各类微动作与表情——无论是指点、手腕抖动、耸肩等肢体姿态,还是微笑、嘲笑等面部神情,都能精准呈现,打破“音频-视觉”的生成壁垒。

- Personalized Restoration:面部精准恢复 + 个性编辑技术,让每一张脸都忠于原貌
Personalized Restoration是一项聚焦面部图像精准修复与个性化编辑的创新技术,核心优势在于既能高效复原受损图像的细节,又能精准捕捉并重现个人独特面部特征,实现“清晰自然”与“身份忠实”的双重保障。