清华大学

- EdgeClaw AI智能体框架使用入口,面壁智能联合清华、OpenBMB等机构推出的开源AI智能体框架
EdgeClaw是面壁智能联合清华、OpenBMB等机构推出的开源AI智能体框架,搭配双轨记忆机制与GuardAgent协议,实现全流程数据管控。简单任务本地处理零Token消耗,复杂任务智能路由云端,已适配松果派、英伟达DGX Spark等硬件,推出EdgeClaw Box开箱即用硬件,让非技术用户也能轻松拥有安全可控的AI数字员工。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
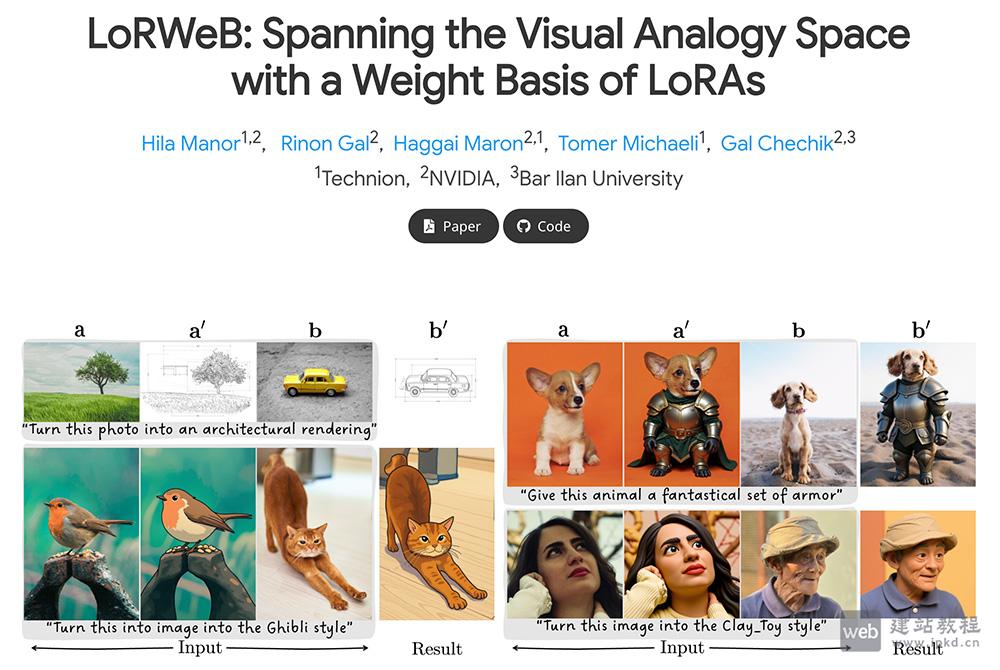
- OpenMAIC官网使用入口,清华THU MAIC研发的开源AI互动教育平台
OpenMAIC是清华大学THU MAIC团队研发的开源AI互动教育平台,致力于将传统被动授课升级为主动、个性化、社交化的AI智能课堂。依托大模型编排与多智能体协同技术,可根据主题或文档一键生成完整互动课程,已通过校内700+学生两年实测验证,高效可靠。平台采用AGPL 3.0开源协议,同时提供商业授权,开源版可免费使用。

- OpenMAIC官网使用入口,清华团队开源的多智能体AI课堂平台
OpenMAIC是由清华团队开源的多智能体AI课堂平台,可将任意主题或文档一键生成沉浸式交互课程。平台支持AI教师语音授课、AI同学互动讨论、白板实时绘图,自动生成幻灯片、测验、交互模拟与项目制学习内容。现已深度接入OpenClaw,可在飞
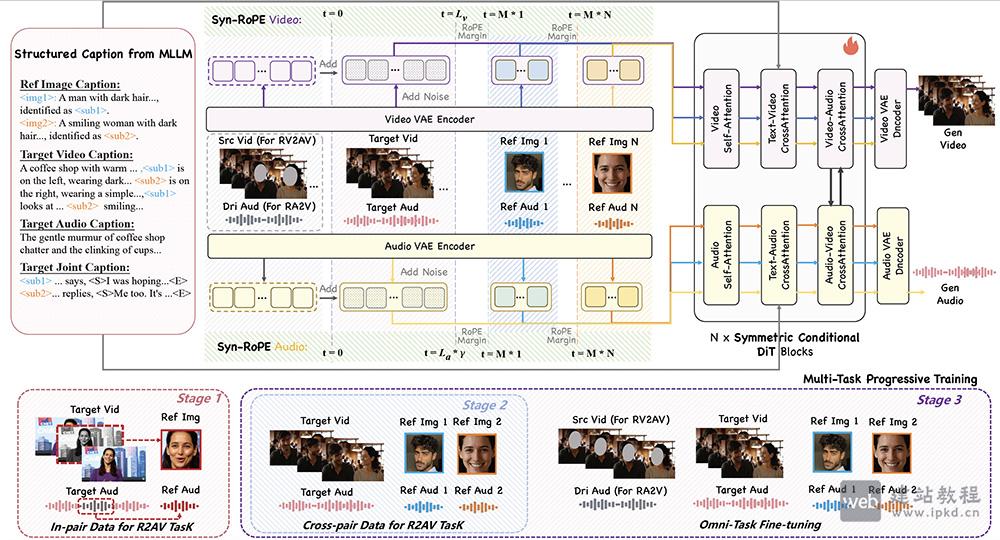
- DreamID-Omni虚拟数字人模型,清华 × 字节跳动统一可控以人为中心音视频生成框架
DreamID-Omni是由清华大学与字节跳动联合研发的统一、可控、以人为中心的音视频生成框架。它打破传统AI视频工具任务割裂的局限,在单一模型内同时实现参考生成、视频编辑、音频驱动动画三大核心能力,多项指标超越主流商业闭源模型,实现了端到端统一架构的重大突破。

- Ctrl-World模型使用入口,厘米级轨迹精度、0.986的策略评估一致性及0.93的深度准确性
Ctrl-World是清华大学陈建宇团队与斯坦福大学Chelsea Finn团队联合研发的具身世界模型,模型创新性融合动作条件化架构与物理引擎约束,将机械臂动作参数显式注入生成流程,实现厘米级轨迹精度、0.986策略评估一致性及0.93深度准确性。

- AgentCPM-Report:清华大学等联合研发的本地化深度调研智能体
AgentCPM-Report是由清华大学自然语言处理实验室、中国人民大学、面壁智能与OpenBMB开源社区联合研发的本地化深度调研智能体,基于8B参数的MiniCPM4.1模型打造。

- C-Eval官网:多学科多层次中文大语言模型权威评估套件
C-Eval是由上海交通大学、清华大学与爱丁堡大学研究团队于2023年5月联合推出的中文大语言模型专属评估套件,包含13948道标准化多项选择题,覆盖52个学科领域、划分四个难度等级。

- DiaMoE-TTS:清华 × 巨人网络联合开源的多方言TTS框架
DiaMoE-TTS是清华大学与巨人网络联合研发的多方言语音合成框架,框架创新性采用国际音标统一输入体系,融合方言感知的混合专家(MoE)架构与低资源适配策略,实现低成本、低门槛的多方言语音合成。

- VoxCPM:0.5B轻量语音生成模型,重塑高保真实时语音合成体验
VoxCPM支持零样本声音克隆,仅需一段参考音频,即可精准复刻说话者的音色、口音、情感语调等细微特征,生成高度逼真的个性化语音。其推理效率同样表现卓越,在NVIDIA RTX 4090 GPU上实时因子(RTF)低至0.17,完美满足实时交互场景需求。

- AgentCPM-Explore:清华等联合研发的轻量级开源智能体模型
AgentCPM-Explore是由清华、人大、面壁智能与OpenBMB开源社区联合研发的轻量级开源智能体模型。该模型仅依托4B参数规模,却在多项长程任务评测基准中超越同尺寸乃至更大参数量的模型,展现出极高的能力密度;同时支持超100轮稳定交互,具备强大的深度探索能力。

- CustomNet:三维增强型对象定制生成技术,商品图融合的革新方案
CustomNet是一个在文本到图像生成领域,将自定义对象(如特定商品)自然融入新场景并完整保留其样式、纹理细节,是极具实用价值的核心需求——尤其为商品图融合、创意设计等场景提供了全新可能。
- DreamTalk:清华联合阿里、华中科大研发,音频驱动的高逼真照片说话框架
DreamTalk是由清华大学、阿里巴巴与华中科技大学联合开发的扩散模型驱动面部动画生成框架,核心能力是让静态人物照片“开口说话”,支持匹配歌曲、多语言语音、嘈杂音频等多种声音类型,生成的唇部动作与表情风格高度自然逼真,打破了传统照片说话技术对纯净音频、表情参考的依赖。

- TurboDiffusion:一款清华、加州大学联合推出的视频生成加速框架
TurboDiffusion是由清华大学、生数科技与加州大学伯克利分校联合研发的重磅视频生成加速框架,凭借多项核心技术突破,实现视频生成效率的跨越式提升。框架创新性融合SageAttention、SLA(稀疏线性注意力)与rCM(时间步蒸馏
- 学堂在线:国内外高校的约8000门优质课程,覆盖13大学科门类
学堂在线运行了来自清华大学、北京大学、复旦大学、中国科技大学以及麻省理工学院等国内外高校的约8000门优质课程,覆盖13大学科门类。
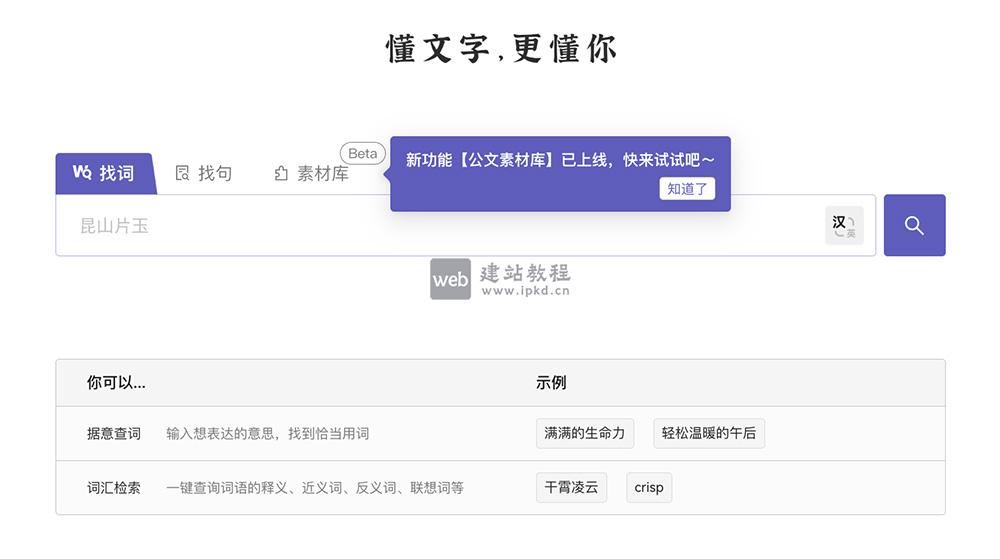
- 深言达意:一款由清华大学和北京智源孵化的智能写作辅助工具
深言达意是一款由清华大学自然语言处理实验室和北京智源人工智能研究院孵化的智能写作辅助工具,旨在帮助用户通过模糊描述找到合适的词语和句子。该工具基于先进的人工智能算法,能够高效、准确地提供写作支持。