语音大模型
- 通义百聆:阿里通义实验室推出的企业级语音基座大模型
通义百聆模型语音合成能力支持跨语种克隆,声音相似度领先。基于海量真实音频训练,覆盖金融、教育等多行业,能快速部署,助力企业高效落地语音应用。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- 豆包语音大模型系列之AI说书
豆包语音大模型系列之AI说书功能通过其强大的语音合成能力和情感表达,为用户提供了媲美真人主播的听书体验。它不仅在技术上实现了突破,还通过实际应用为用户带来了更加丰富和自然的听书选择。
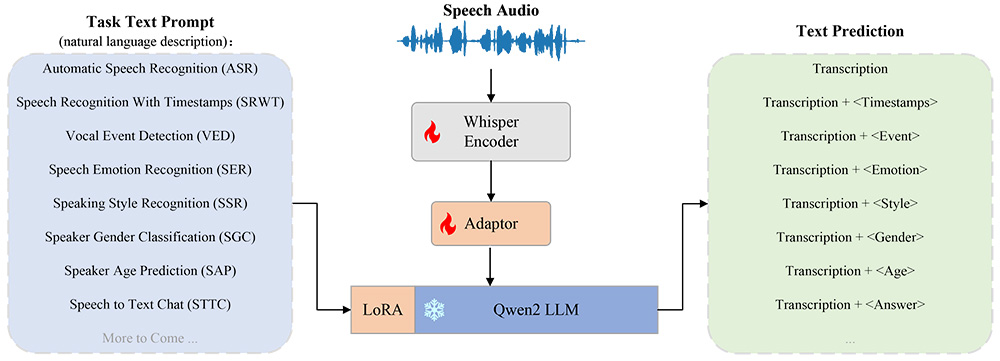
- 一款由西北工业大学 ASLP 实验室开发的开源语音理解模型——OSUM
OSUM支持8种语音任务,包括语音识别(ASR)、带时间戳的语音识别(SRWT)、语音事件检测(VED)、语音情感识别(SER)、说话风格识别(SSR)、说话人性别分类(SGC)、说话人年龄预测(SAP)以及语音转文本聊天(STTC)。

- TIGER:一款由清华大学研发的轻量级语音分离模型
实验结果显示,TIGER在EchoSet数据集上的表现优于其他模型,尤其是在EchoSet-500数据集上,性能提升了约5%。此外,TIGER在电影音频分离任务中也展现了强大的泛化能力,进一步证明了其在复杂声学环境中的适用性。