Meta AI
- Facebook推出三款AI全新功能——动态头像、Stories与照片重塑工具
Facebook推出动态头像、照片Restyle重塑、文本动态背景三大AI功能,核心是提升内容表达的个性化与生动性;本次更新本质是Facebook应对用户老化的关键动作,试图通过AI技术吸引年轻用户回流。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- Omnilingual ASR:Meta AI推出的千亿级语言自动语音识别系统
Omnilingual ASR采用社区驱动的扩展框架,用户仅需提供少量语音-文本样本,即可快速将系统适配至新语言;同时 Meta 开源了Omnilingual ASR Corpus数据集与全新自监督式大规模多语言语音表示模型Omnilingual wav2vec 2.0,为全球语音技术研发提供核心支撑,助力推动语言平等与跨文化交流。

- CWM:Meta开源320亿参数代码世界模型,重构AI代码生成新范式
CWM是Meta重磅开源的320亿参数代码世界模型,作为全球首个将世界模型技术系统性引入代码生成领域的语言模型,它彻底打破传统代码模型“模式匹配”的局限,以“模拟代码执行过程”的核心能力,实现代码生成与理解的双重突破,为AI辅助软件开发开辟全新路径。

- Meta ARE:Meta出品,面向AI Agents的动态模拟研究与评估平台
Meta ARE是Meta推出的专业研究平台,聚焦于AI Agents的训练与系统性评估。该平台通过构建随时间动态演变的模拟环境,还原真实世界的复杂多步骤任务场景,要求Agents能够根据新信息的出现和环境条件的变化,实时调整决策策略。

- Audio2PhotoReal:Meta AI重磅技术,音频直驱超写实全身虚拟人物生成
Audio2PhotoReal生成的虚拟人物不仅视觉质感逼真,更能细腻复刻对话中的各类微动作与表情——无论是指点、手腕抖动、耸肩等肢体姿态,还是微笑、嘲笑等面部神情,都能精准呈现,打破“音频-视觉”的生成壁垒。
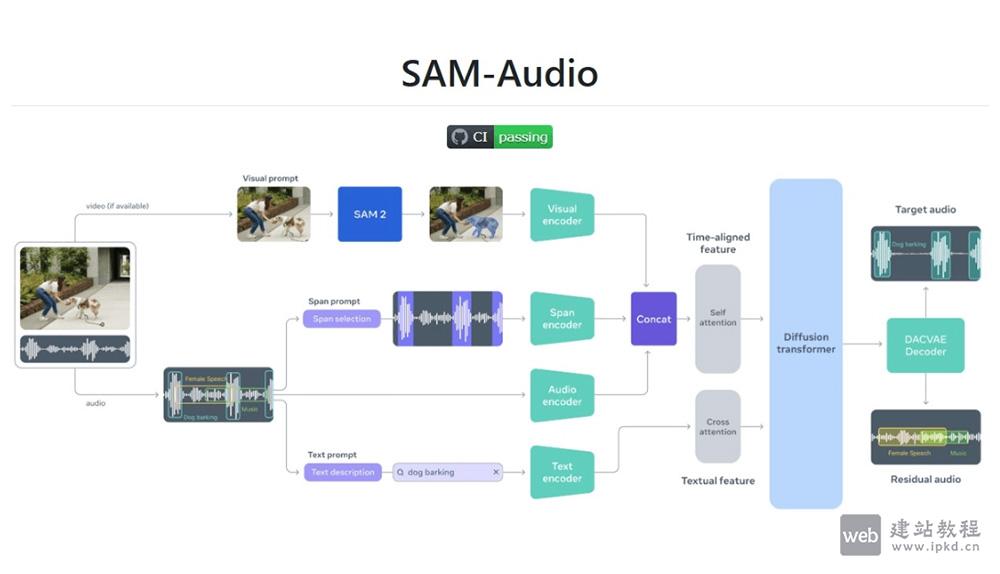
- SAM Audio:Meta开源多模态音频分割模型,精准分离复杂声音场景
SAM Audio是Meta开源的音频分割模型,能通过文本、视觉和时间片段等多模态提示,从复杂的音频混合中分离出特定的声音。
- LLaMA:Meta(Facebook)推出的AI大语言模型
LLaMA是一组基础语言模型集合,参数规模从7亿到650亿不等,涵盖了不同的版本如7B、13B、33B、65B等。这些模型在数万亿个token上进行训练,展示了使用公开数据集也能达到先进水平的能力。
- V-JEPA:一款由Meta AI发布的AI新型视频学习模型(附论文网址及博客网址)
V-JEPA 是一种创新的自监督学习模型,通过预测视频帧的特征表示来学习视频的视觉表示。它不仅能够处理视频内容,还在图像任务上表现出色,具有广泛的应用潜力。