AI视觉语言模型

- FireRed-OCR小红书开源模型,轻量级文档结构解析VLM
FireRed-OCR是小红书团队开源的轻量级文档结构解析视觉语言模型,基于Qwen3-VL-2B-Instruct架构,采用三阶段渐进式训练。FireRed-OCR专为解决文档结构幻觉设计,可精准提取表格、公式、标题层级,并输出标准Markdown,兼顾高精度与轻量化部署。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- Actio Ui 7b Rlvr GGUF:Uniphore官方发布的70亿参数GUI自动化视觉语言模型
ActIO-UI-7B-RLVR作为一款专为GUI自动化量身打造的视觉语言模型,其核心优势的是能够精准理解屏幕截图内容,快速识别界面中的各类元素,结合用户指令自主规划多步骤交互流程,并执行点击、输入等操作,无需人工干预即可实现网页、桌面应用的自动化控制,大幅提升各类界面操作的效率与标准化程度。

- Thinker:优必选开源具身智能视觉语言大模型 专为机器人场景打造
Thinker模型聚焦机器人核心需求,打造任务规划、空间理解、时间推理、视觉定位四大核心能力,精准解决机器人“想得到但抓不准”的行业痛点。模型基于20亿原始数据精炼的1000万高质量数据训练,依托自动化标注体系将人工参与率控制在1%以下,兼顾训练效率与数据质量。

- FG-CLIP 2:360推出的新一代开源双语细粒度视觉语言对齐模型
FG-CLIP 2是360推出的新一代开源双语细粒度视觉语言对齐模型,模型凭借创新的层次化对齐架构与动态注意力机制,在29项权威基准测试中超越Google SigLIP 2、Meta MetaCLIP 2等主流模型,跻身全球顶尖视觉语言模型行列。

- DeepSeek-OCR:DeepSeek团队开源的高效长文本视觉语言处理模型
DeepSeek-OCR是DeepSeek团队研发的一款视觉语言模型,主打基于视觉压缩技术的长文本高效处理能力。该模型采用DeepEncoder编码器+DeepSeek3B-MoE解码器的架构,可在保留高分辨率输入信息的前提下,大幅降低激活内存占用与视觉标记数量。

- SAIL-VL2:抖音 × 新加坡国立大学联合开源的视觉语言模型
SAIL-VL2是抖音团队与新加坡国立大学联合研发的开源视觉语言基础模型,模型由SAIL-ViT视觉编码器、视觉-语言适配器与大语言模型三大核心模块构成,创新性采用渐进式训练框架,从视觉预训练、多模态融合,到最终的SFT-RL混合范式优化,实现性能阶梯式跃升。

- Granite-Docling-258M:IBM轻量级视觉语言模型
Granite-Docling-258M模型支持阿拉伯语、中文、日语等多语言处理,并创新性采用DocTags格式精准描述文档结构,搭配与Docling库的无缝集成能力,赋予用户强大的定制化空间与错误处理机制,成为企业级文档智能化升级的高效利器。

- Helix:一款由Figure AI发布的新型通用视觉语言动作(VLA)模型
一款由Figure AI发布的新型VLA(视觉-语言-动作)模型,能够通过自然语言指令控制人形机器人的动作。它支持全上半身控制,实现高精度动作协调,还支持多机器人协作。
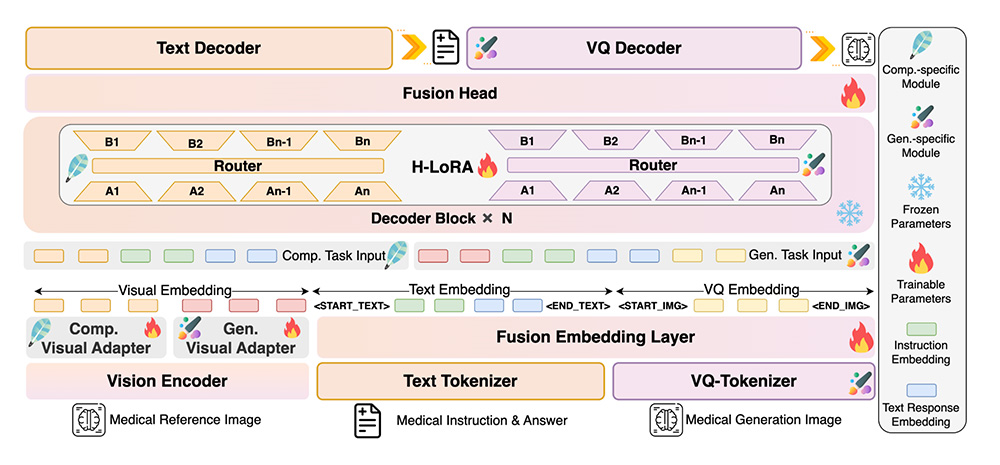
- 一款由浙大阿里巴巴等多家机构联合开发的先进医学视觉语言模型——HealthGPT
HealthGPT一款由浙江大学、电子科技大学、阿里巴巴等多家机构联合开发的先进医学视觉语言模型(Med-LVLM),它能够处理多种医学图像(如X光、CT、MRI等),并提供诊断建议、视觉问答和医学文本生成等功能。