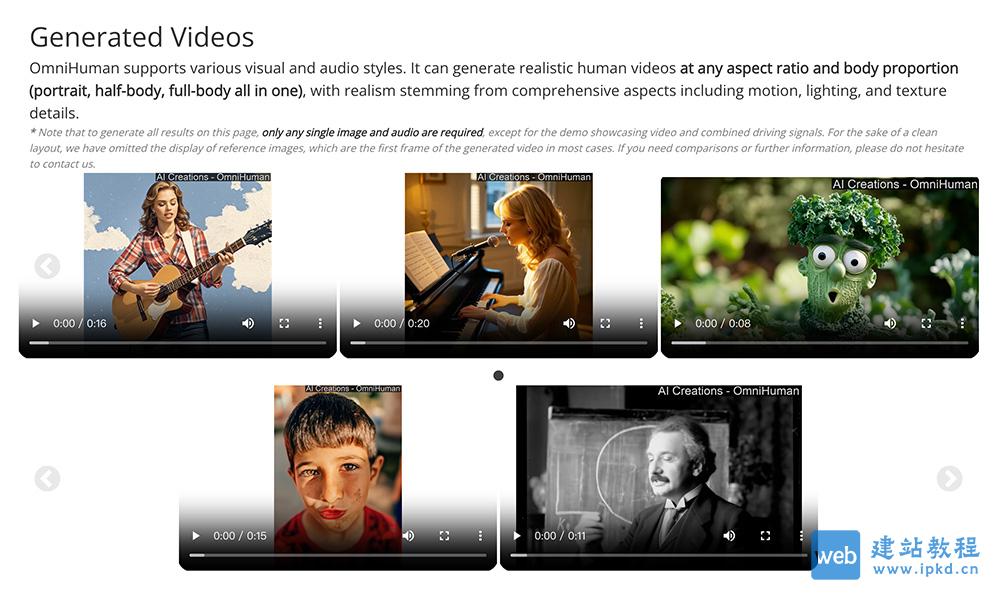
OmniHuman是由字节跳动推出的一款端到端的多模态数字人视频生成框架,能够基于单张人物图像和运动信号(如音频、视频或两者的结合)生成逼真的人像视频。该技术的核心在于其创新的多模态运动条件混合训练策略,使得模型能够从大规模、多样化的数据中学习,克服了以往方法因高质量数据稀缺而表现不佳的问题。
OmniHuman功能特点:
1、多模态输入支持:
- 支持多种输入信号,包括文本、图像、音频和姿态。
- 可以处理单一图像与音频、视频或音频与视频结合的输入。
2、逼真的视频生成:
- 生成的视频具有高度逼真的动作、光照和纹理细节。
- 支持各种比例和身形的人像视频(如头像、半身像、全身像),不受画面尺寸限制。
3、强大的适应性:
- 支持多种场景,包括讲解、手势、唱歌等。
- 能够处理复杂的肢体动作和人与物体的互动。
4、多样化的风格支持:
- 不仅支持逼真的输出,还支持卡通、风格化和拟人化的角色动画。
- 适配卡通、人工物体及动物等多样化输入。
5、灵活的驱动方式:
- 支持音频驱动、视频驱动以及两者的结合。
- 可以模仿特定视频中的动作,并精确控制不同的身体部位。
6、高效的数据利用:
- 采用渐进式、多阶段训练方法,根据不同条件对运动的影响程度进行分阶段训练。
- 通过混合条件训练,充分利用大规模、多样化数据,提升生成效果。
OmniHuman应用场景:
1、演讲和讲解:生成基于 TED 演讲的音频驱动讲解视频。
2、广告和短视频制作:生成不同体态的肖像和全身人类视频。
3、音乐和唱歌视频:生成多种音乐风格的唱歌视频,包括高音和各种姿势变化。
4、虚拟化身和数字故事:生成自然的头部运动和细致的手部互动,特别适合虚拟化身和数字故事。
相关阅读文章
SoulX-LiveAct模型官网 - Soul App开源实时数字人流式生成框架
Protenix-v1模型使用入口,开源生物分子结构预测的新标杆
BitDance模型使用入口,字节跳动正式开源的140亿参数离散自回归多模态基础模型
Seed2.0模型官网使用入口,字节跳动Seed团队推出的新一代通用Agent大模型家族
Seedream 5.0 Lite模型官网使用入口,字节跳动新一代AI图像创作模型
上面是“OmniHuman:字节推出的一款端到端的多模态数字人视频生成框架”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://ipkd.cn/webs_22935.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!