字节跳动框架
- Protenix-v1模型使用入口,开源生物分子结构预测的新标杆
Protenix-v1是字节跳动Seed团队开源的生物分子结构预测模型,首个在同等条件下(数据截止2021-09-30、相同模型规模和推理预算)性能达到甚至超越AlphaFold3的完全开源方案。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- BitDance模型使用入口,字节跳动正式开源的140亿参数离散自回归多模态基础模型
BitDance是字节跳动正式开源的140亿参数离散自回归多模态基础模型。凭借创新的二进制Token编码机制与并行扩散预测范式,模型在保持高分辨率、高保真画质的前提下,实现了颠覆性的生成速度,效率较传统自回归模型提升30倍以上,甚至超越多款主流扩散模型。
- Seed2.0模型官网使用入口,字节跳动Seed团队推出的新一代通用Agent大模型家族
Seed 2.0是字节跳动Seed团队自研推出的新一代通用Agent大模型家族,由Pro/Lite/Mini三款通用模型与Code专用模型组成,全面升级多模态理解、长上下文处理与复杂任务执行能力,兼顾顶尖性能与普惠成本。
- Seedream 5.0 Lite模型官网使用入口,字节跳动新一代AI图像创作模型
Seedream 5.0 Lite核心优势是多模态统一架构+实时联网检索,视觉推理精准、内容时效性强,支持风格迁移、高阶编辑等专业功能;可通过即梦AI、火山方舟、豆包App(内测)使用,覆盖办公、营销、影视、艺术、社交等全场景图像创作需求。
- Seedance 3.0模型官网使用入口,字节跳动AI视频生成器
Seedance 3.0是字节跳动推出的低门槛AI视频生成器,核心优势为广播级画质、文本转视频、多风格创作,适配电商/网红/开发者等多人群;支持批量处理、无水印下载、API拓展等商用级功能,付费套餐限时50%折扣,性价比突出。
- Seedance 2.0 Pro官网使用入口,字节跳动自研、基于即梦AI模型的AI视频生成平台
Seedance 2.0 Pro是由字节跳动自研、基于Jimeng AI模型的AI视频生成平台,依托字节跳动领先技术,打造专业级AI视频创作能力。平台核心优势为流畅相机运动、时间一致性、复杂场景深度理解与高效视频生成。
- Seedream 4.5模型使用入口,火山方舟、豆包、即梦AI等平台直接体验
Seedream 4.5是字节跳动专为商业生产力打造的新一代AI图像生成模型,在主体一致性、指令遵循、空间逻辑与美学质感上全面升级,重点强化多图自然融合能力,可无缝支撑广告、电商、影视、教育、数字娱乐等核心场景。
- Seedream 5.0官网使用入口,支持2K直出、AI增强至4K高清画质
Seedream 5.0是字节跳动推出的新一代知识型AI图像生成模型,行业首创联网检索生图能力,精准理解复杂抽象提示词,原生支持2K直出、AI增强至4K高清画质,并新增笔刷精细化编辑功能,官方对标行业顶尖模型Nano Banana Pro。
- Seedance 2.0:模型支持首尾帧、视频片段、音频多维度综合参考
Seedance 2.0是一款新一代AI视频生成模型,模型支持首尾帧、视频片段、音频多维度综合参考,可精准复刻运镜逻辑、动作细节与音乐氛围,生成效率高效,15秒视频约消耗30积分。
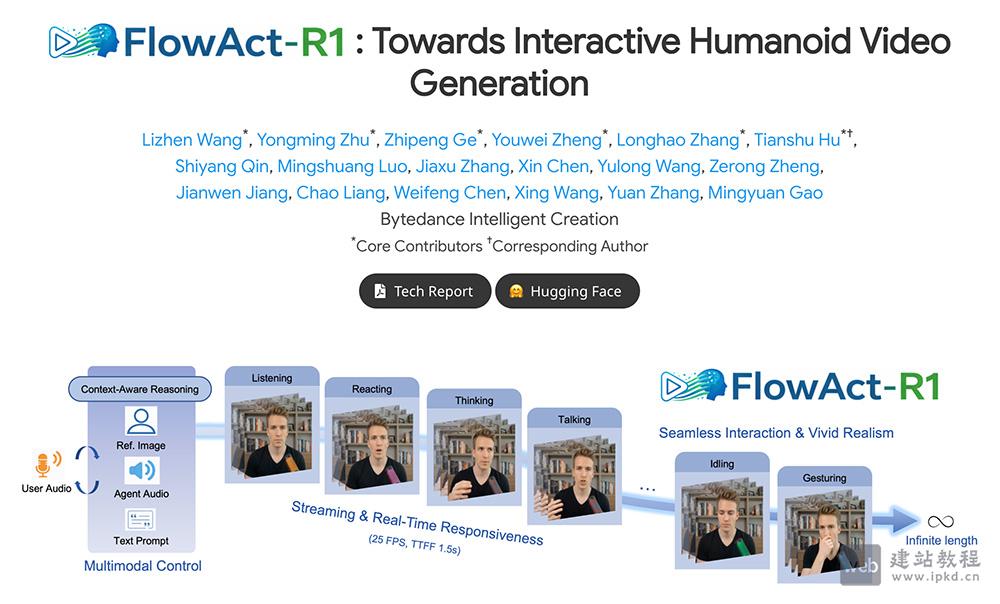
- FlowAct-R1:字节跳动推出的实时交互数字人视频生成框架
FlowAct-R1是字节跳动推出的实时交互数字人视频生成框架,该框架凭借分块扩散强制策略、多模态大语言模型等核心技术,实现1.5秒首帧低延迟与25fps稳定实时响应,可精细调控数字人面部表情和肢体动作。
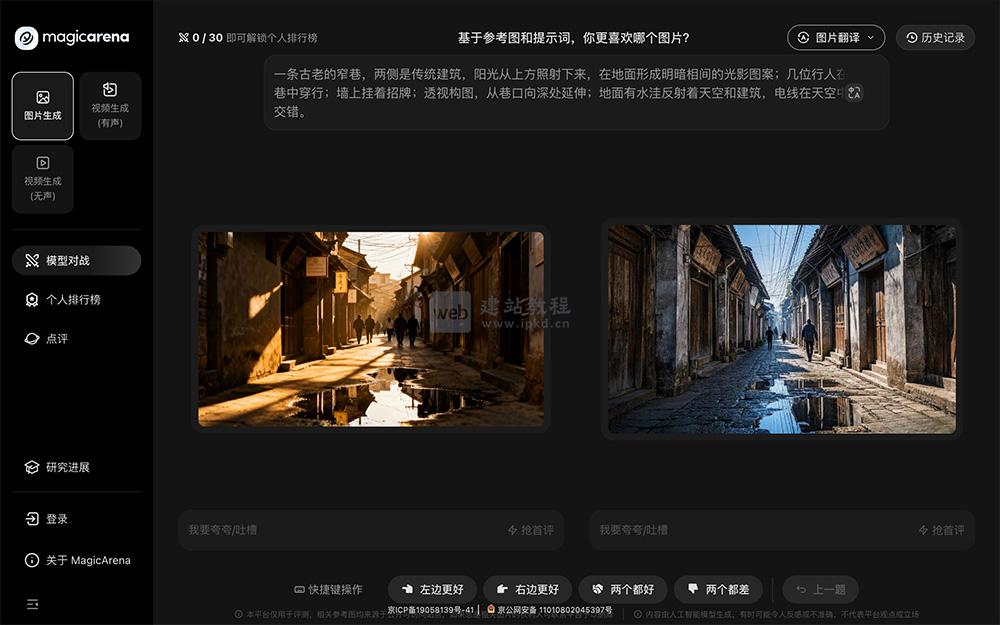
- MagicArena:字节跳动国内首个视觉生成大模型对战平台
MagicArena是字节跳动推出的国内首个视觉生成大模型对战平台,平台支持用户输入文字提示词,一键调用Midjourney、FLUX、可灵、海螺、即梦等国内外主流视觉生成大模型,同步生成图片或视频内容。

- Seed Prover 1.5:字节跳动Seed团队研发的形式化数学推理模型
Seed Prover 1.5是字节跳动Seed团队研发的新一代形式化数学推理模型,该模型创新性采用Agentic Prover架构,依托大规模强化学习(Agentic RL)完成训练,实现数学推理能力与效率的双重跃升。

- Seedance 1.5 Pro:字节团队研发的原生音画同步多模态视频生成模型
Seedance 1.5 Pro是字节跳动Seed团队研发的原生音画同步多模态视频生成模型,支持通过文本指令生成高质量视频内容,覆盖多语言、多方言及多样人声与音效。

- Vidi2:字节跳动多模态大语言模型,赋能视频理解与智能创作
Vidi2是字节跳动推出的专注于视频理解与创作的多模态大语言模型,模型可基于文本查询,精准识别视频对应时间戳并标记目标对象边界框,还创新引入VUE-STG、VUE-TR-V2两大基准测试,为STG能力评估提供更科学的标准。

- InfinityStar:字节跳动推出的高效开源视频生成模型
InfinityStar是字节跳动推出的高效视频生成模型,该模型支持文本到图像、文本到视频、图像到视频及长时间交互视频合成等多类任务,且所有代码与模型均已开源。