AI模型评测

- PubMedQA:一个面向生物医学研究问题回答的专业数据集工具
PubMedQA是面向生物医学研究问题回答的专业数据集,该数据集包含1000个专家标注问答实例、61200个未标注实例及211300个人工生成问答对,为生物医学自然语言处理模型提供标准化测试基准,助力研发人员开发和评估模型,提升其对生物医学文献的理解与问答能力。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
- H2O EvalGPT:H2O.ai推出的开源LLM大模型评估工具
H2O EvalGPT是H2O.ai推出的开源LLM大模型评估工具,为用户提供一站式平台,用于全面洞察各类大模型在海量任务及基准测试中的性能表现。无论你是希望通过大模型自动化工作流程、优化业务任务,该工具都能提供主流开源高性能大模型的详细排行榜,助力精准筛选适配项目需求的最优模型,高效完成特定任务。

- LLMEval3:复旦大学NLP实验室推出的第三代中文大模型专业知识评测基准
LLMEval3是目前国内外最权威的大语言模型(LLM)专业知识评测基准之一。它由复旦大学自然语言处理实验室推出,旨在填补通用模型评测中对学科深度和专业应用能力的空白。

- LMArena:加州大学伯克利分校推出基于用户投票的AI模型评估平台
LMArena是加州大学伯克利分校推出的AI模型评估平台,用户输入问题后,平台同步输出两个AI模型的匿名回答,用户投票选出更优答案,投票结果实时反馈至公共排行榜,直接决定模型排名。

- HELM官网:斯坦福大学推出的语言模型整体评估体系
HELM是斯坦福大学推出的大模型评测体系。其核心评测框架包含场景、适配、指标三大核心模块,每次评测需明确指定一个应用场景、一套模型适配提示,以及一项或多项评估指标。

- MMBench:一款由高校等联合研发多模态基准测试工具
MMBench是一款多模态基准测试工具,由上海人工智能实验室、南洋理工大学、香港中文大学、新加坡国立大学及浙江大学联合研发。该基准构建了一套从感知到认知的逐级细分评估流程,覆盖20项细粒度能力维度,数据集包含约3000道单项选择题,均源自互联网及权威基准数据集。
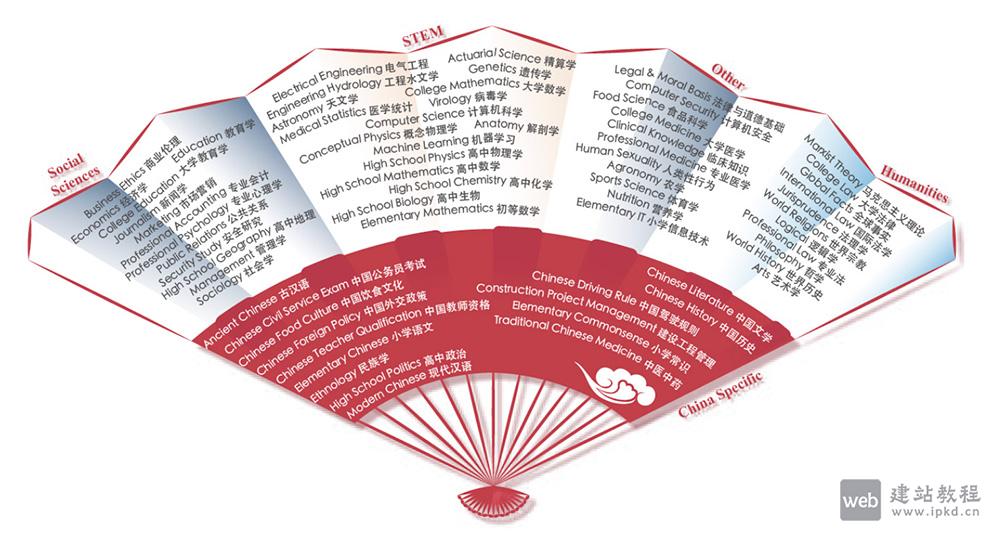
- CMMLU:专注衡量语言模型的中文知识储备与推理能力的大模型中文评估基准
CMMLU是面向中文语境的综合性评估基准,专注衡量语言模型的中文知识储备与推理能力,覆盖67个从基础学科到高级专业的主题。其任务范畴横跨三类领域:需计算推理的自然科学、需知识沉淀的人文与社会科学、需生活常识的中国驾驶规则等场景。
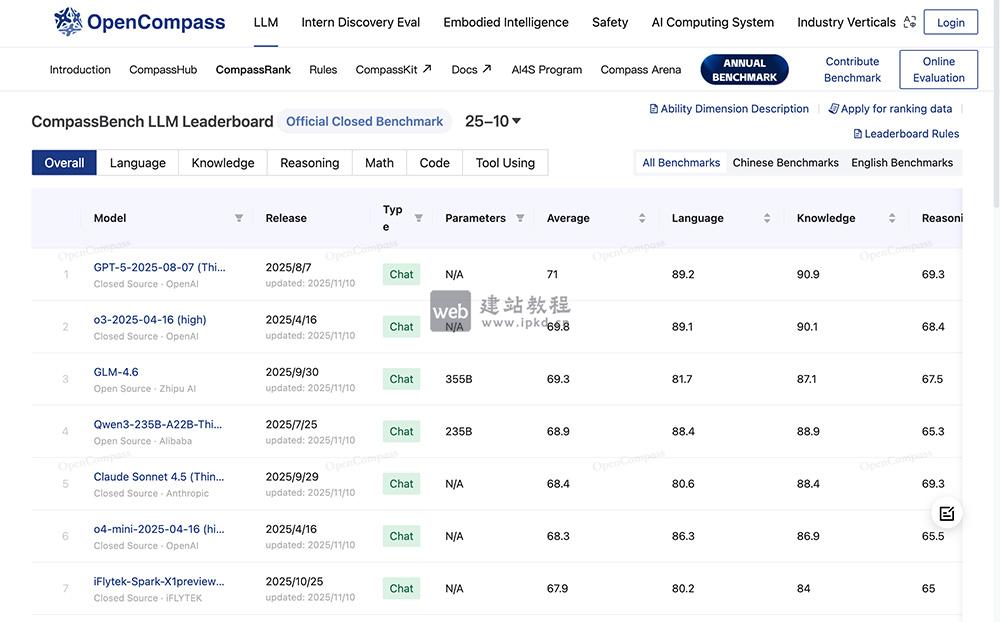
- OpenCompass:上海AI实验室开源的大模型一站式开放评测体系
>OpenCompass是上海AI实验室正式推出的大模型全品类开放评测体系,以完整开源、可复现的评测框架为核心,实现大语言模型、多模态模型的一站式评测,且定期发布权威评测结果榜单。
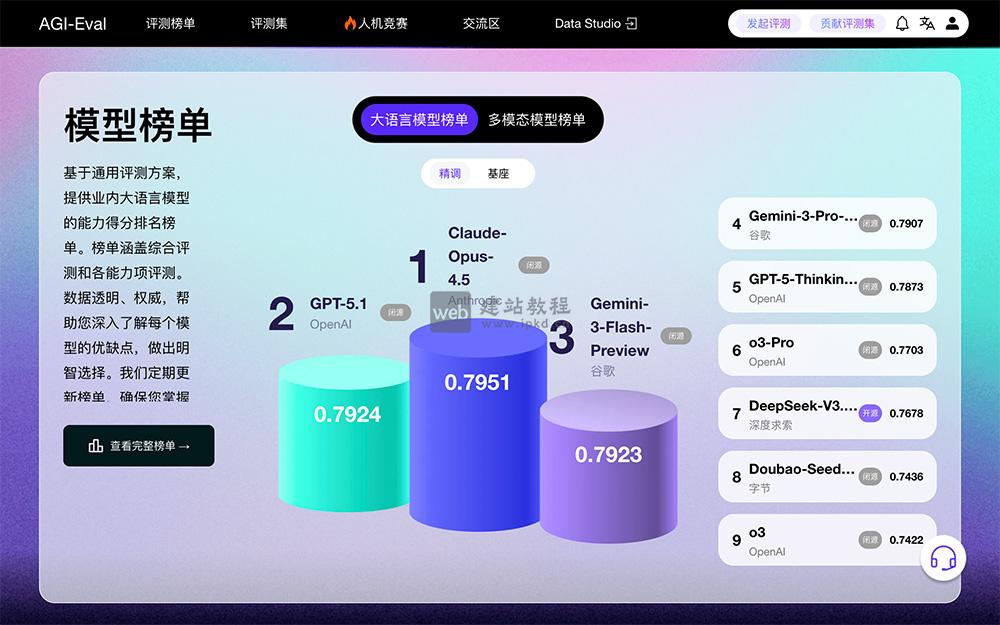
- AGI-Eval:高校联合打造的大模型通用能力评测社区与生态平台
AGI-Eval是由上海交通大学、同济大学、华东师范大学、DataWhale等高校及机构联合打造的大模型通用能力评测社区,以“评测助力,让AI成为人类更好的伙伴”为核心使命,致力于构建公正、可信、科学、全面的大模型评测生态。平台专为评估基础
- SuperCLUE官网:一个中文大模型的全维度综合性评测基准
SuperCLUE是聚焦中文大模型的全维度综合性评测基准,其以四大能力象限、12项基础能力为核心评测框架,融合多轮对话、客观题测试、主观题评估等多元评测方式,从语言理解与生成、知识应用、专业技能、环境适应与安全性四大维度展开全面评测。

- FlagEval:智源研究院打造的大模型全维度科学评测体系与开放平台
平台多维度拆解大模型认知能力,覆盖对话、问答、情感分析等多元应用场景;配套超22个专业数据集、8万道评测题目,同时支持文本、图像、视频等多模态模型评测,兼容PyTorch、MindSpore等多AI框架及NVIDIA、昇腾等多硬件架构。

- C-Eval官网:多学科多层次中文大语言模型权威评估套件
C-Eval是由上海交通大学、清华大学与爱丁堡大学研究团队于2023年5月联合推出的中文大语言模型专属评估套件,包含13948道标准化多项选择题,覆盖52个学科领域、划分四个难度等级。

- Open LLM Leaderboard:HuggingFace开源大模型权威评估排行榜
Open LLM Leaderboard是全球最大的大模型与数据集社区HuggingFace推出的开源大模型专业排行榜单,平台通过IFEval、BBH、MATH等多类权威基准测试,从指令遵循、复杂推理、数学解题、专业知识问答等核心维度对大模型进行全方位量化评估。

- MMLU测评官网:一种专注于评估大模型综合能力的基准测试工具
MMLU(大规模多任务语言理解)是一种专注于评估大模型综合能力的基准测试工具。它通过涵盖多个学科领域的问答任务,来测量模型的世界知识深度、跨领域推理能力和学术水平。
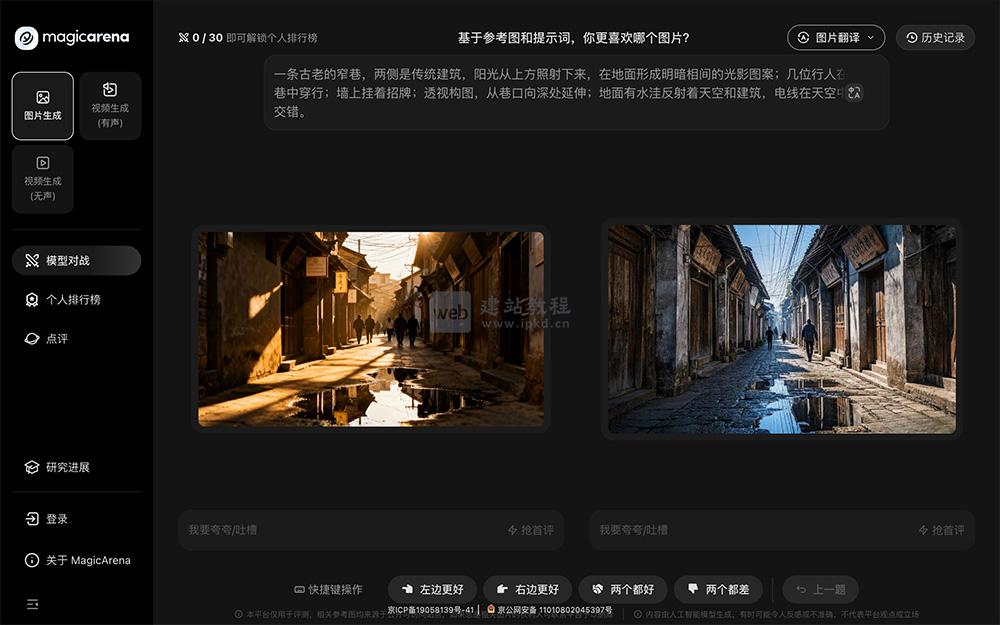
- MagicArena:字节跳动国内首个视觉生成大模型对战平台
MagicArena是字节跳动推出的国内首个视觉生成大模型对战平台,平台支持用户输入文字提示词,一键调用Midjourney、FLUX、可灵、海螺、即梦等国内外主流视觉生成大模型,同步生成图片或视频内容。