AI视频生成模型
- PixVerse V6模型官网 - 爱诗科技全新一代AI视频生成模型
模型支持单提示词直接生成带原生音频的多镜头短片,无需后期剪辑;同时新增多语言画面文本生成能力,并开放CLI接口,可无缝对接Claude Code、Codex等编程Agent,兼顾创意创作与自动化批量生产。目前已面向所有用户开放使用。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- Solaris多人视频模型官网入口,累计收集1260万帧多人游戏标注数据
团队自研SolarisEngine数据系统,累计收集1260万帧多人游戏标注数据,并创新推出Checkpointed Self Forcing训练方法,高效解决长序列生成的内存瓶颈,为多智能体研究、具身智能训练等场景提供高保真、可可控的多人世界模拟解决方案。
- Seedance 3.0模型官网使用入口,字节跳动AI视频生成器
Seedance 3.0是字节跳动推出的低门槛AI视频生成器,核心优势为广播级画质、文本转视频、多风格创作,适配电商/网红/开发者等多人群;支持批量处理、无水印下载、API拓展等商用级功能,付费套餐限时50%折扣,性价比突出。
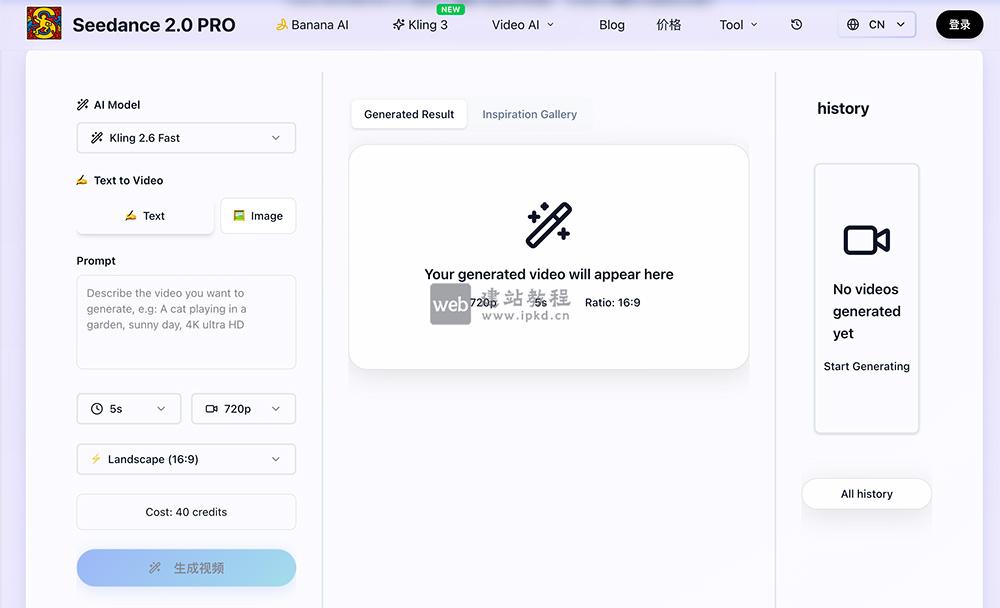
- Seedance 2.0 Pro官网使用入口,字节跳动自研、基于即梦AI模型的AI视频生成平台
Seedance 2.0 Pro是由字节跳动自研、基于Jimeng AI模型的AI视频生成平台,依托字节跳动领先技术,打造专业级AI视频创作能力。平台核心优势为流畅相机运动、时间一致性、复杂场景深度理解与高效视频生成。
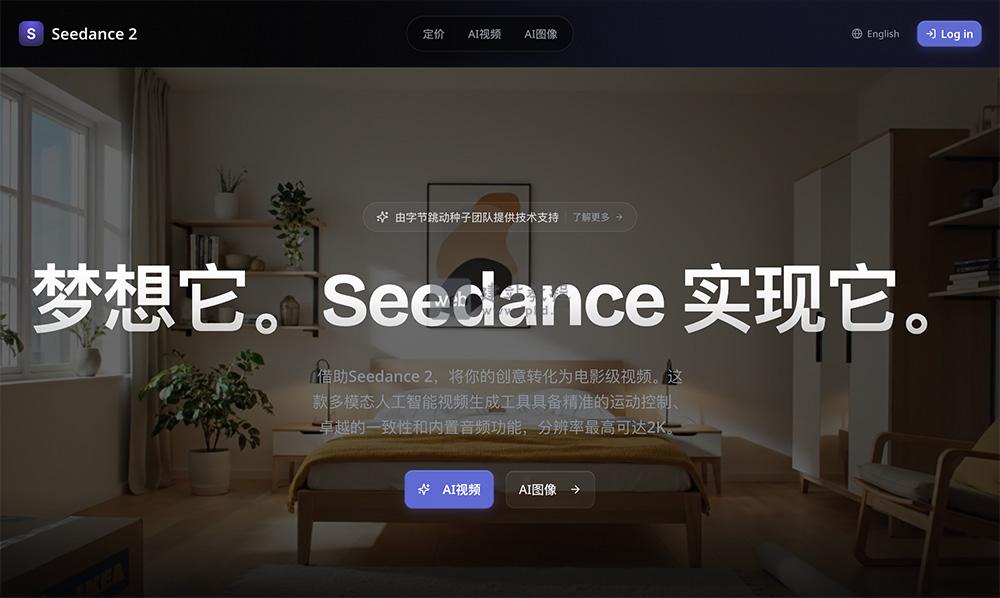
- Seedance 2:字节跳动多模态AI视频生成模型,电影级创意落地工具
Seedance 2 是字节跳动重磅推出的多模态AI视频生成模型,模型支持图像、视频、音频、文本多模态输入,可通过自然语言描述精准参考任意内容,其核心价值在于打破传统视频创作的技术壁垒,为创作者提供精确运动复制、高度统一视觉风格的创作工具,助力从创意构思到成品输出的全流程高效落地。
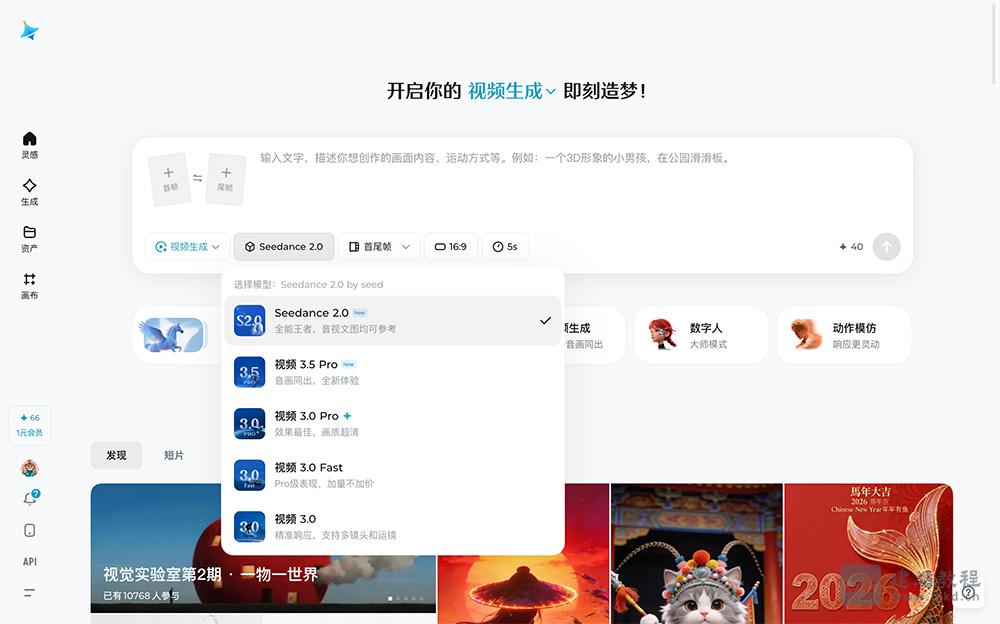
- Seedance 2.0:模型支持首尾帧、视频片段、音频多维度综合参考
Seedance 2.0是一款新一代AI视频生成模型,模型支持首尾帧、视频片段、音频多维度综合参考,可精准复刻运镜逻辑、动作细节与音乐氛围,生成效率高效,15秒视频约消耗30积分。
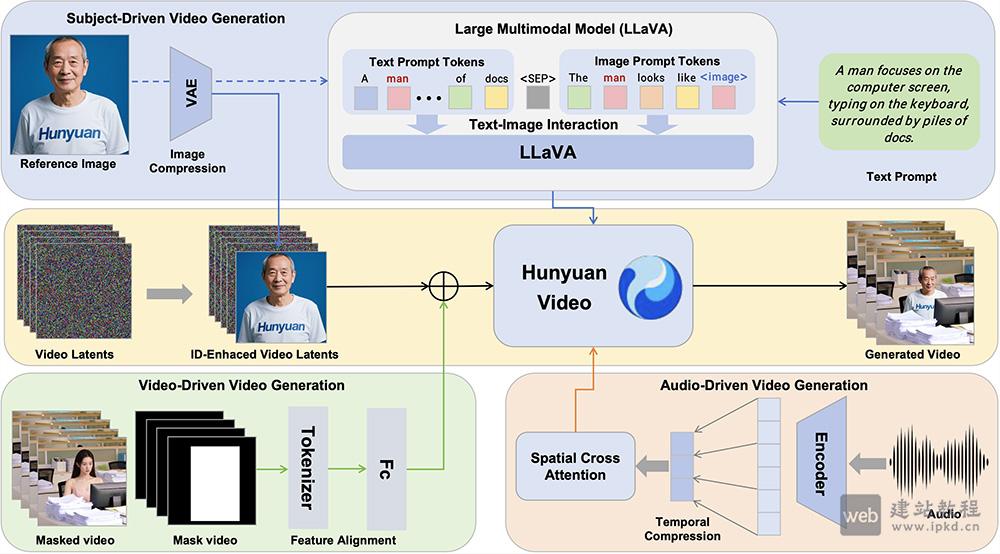
- HunyuanCustom:支持文本、图像、音频、视频多模态输入的多模态定制视频生成框架
HunyuanCustom是一款多模态定制视频生成框架,可根据用户自定义条件,精准生成特定主题的定制化视频。该框架在人物身份一致性上表现突出,全面支持文本、图像、音频、视频多模态输入,适配虚拟人广告制作、个性化视频编辑等多元应用场景,为创作者提供高效的视频定制解决方案。
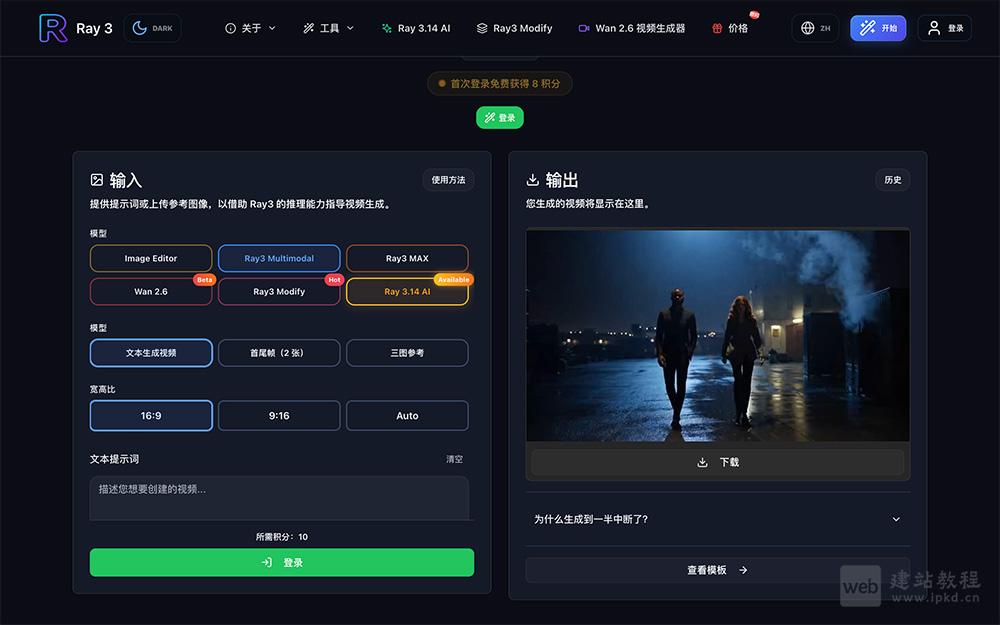
- Luma Ray3AI:全球首个具备推理能力的AI视频模型
Luma Ray3AI是由Luma Ray3打造的全球首个具备推理能力的视频模型,可通过智能思考、规划创作专业级视频内容,搭载原生HDR生成、智能草稿模式等核心能力,能深度理解创作需求、快速完成内容迭代。
- Lucy 2.0:Decart AI实时世界转换模型,重构高保真视觉编辑体验
Lucy 2.0能有效校正长期运行中的质量漂移问题,实现数小时不间断的连贯生成。针对AWS Trainium3硬件深度优化后,模型可广泛应用于实时角色替换、虚拟试装等视觉特效场景,同时为机器人训练提供物理一致的实时数据增强与模拟环境。
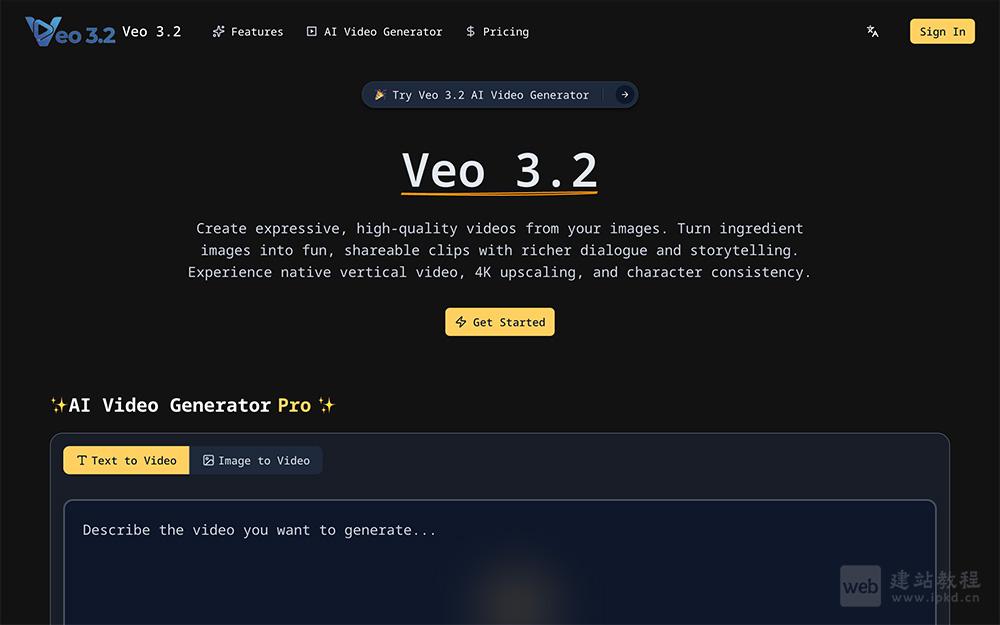
- Veo 3.2:一款增强型AI视频生成模型,高质量动态视频
Veo 3.2是一款增强型AI视频生成模型,该模型凭借角色与场景一致性、原生竖屏支持、4K超分等核心优势,大幅降低专业视频制作门槛,无论是业余爱好者还是专业创作者,都能高效实现创意落地。
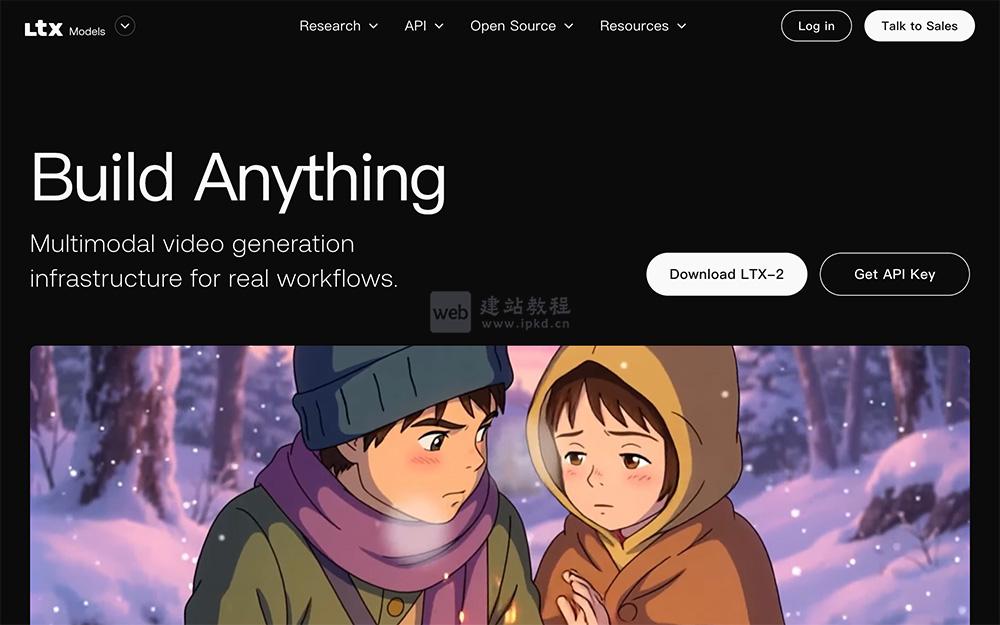
- LTX-2:Lightricks旗舰级/电影级多模态AI视频生成模型
LTX-2是Lightricks研发的先进AI视频生成模型,专为专业级高质量视频创作打造。该模型可原生输出4K分辨率、50fps帧率的电影级视频,支持文字、图片、草图多模态输入,并提供镜头角度、物体动作、时间节奏等精细化控制能力。
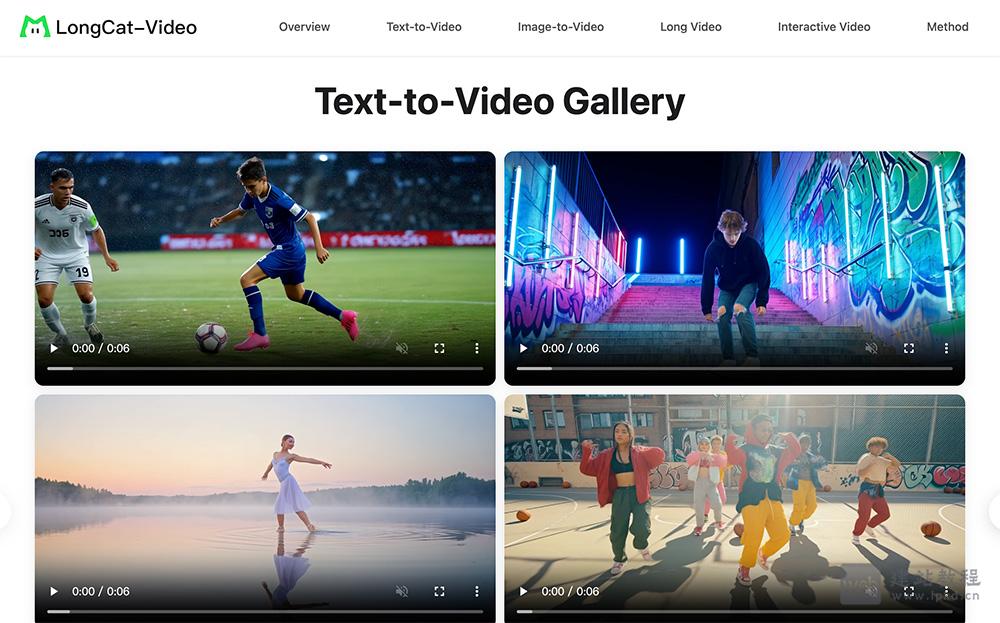
- LongCat-Video:美团开源136亿参数高效AI长视频生成模型
LongCat-Video是美团LongCat团队研发的136亿参数开源AI视频生成模型,支持文本到视频(Text-to-Video)、图像到视频(Image-to-Video)及视频续写(Video-Continuation)全任务流程,核心优势在于高效生成高质量长视频。

- Veo 3.1:谷歌新一代AI视频生成模型,重构创意生产全流程
Veo 3.1是谷歌推出的旗舰级AI视频生成模型,支持文本提示、图像、视频片段等多模态输入,可直接生成720P、1080P乃至4K高清视频,让用户在生成阶段即可完成音画同步的完整创作,无需额外后期处理。

- 通义万相2.6:阿里云推出的最新一代AI视频与图像生成模型
通义万相2.6是阿里云推出的最新一代AI视频与图像生成模型,于2026年1月正式发布。作为通义万相模型家族的最新版本,它在视频生成和图像创作方面实现了重大突破,是国内首个支持角色扮演功能的视频模型。

- Sora 2:OpenAI新一代多模态音视频生成模型
Sora 2是OpenAI推出的新一代AI音视频生成模型,该模型实现三大核心技术突破:依托多模态联合训练,首次达成环境音效与画面动态的实时同步生成。