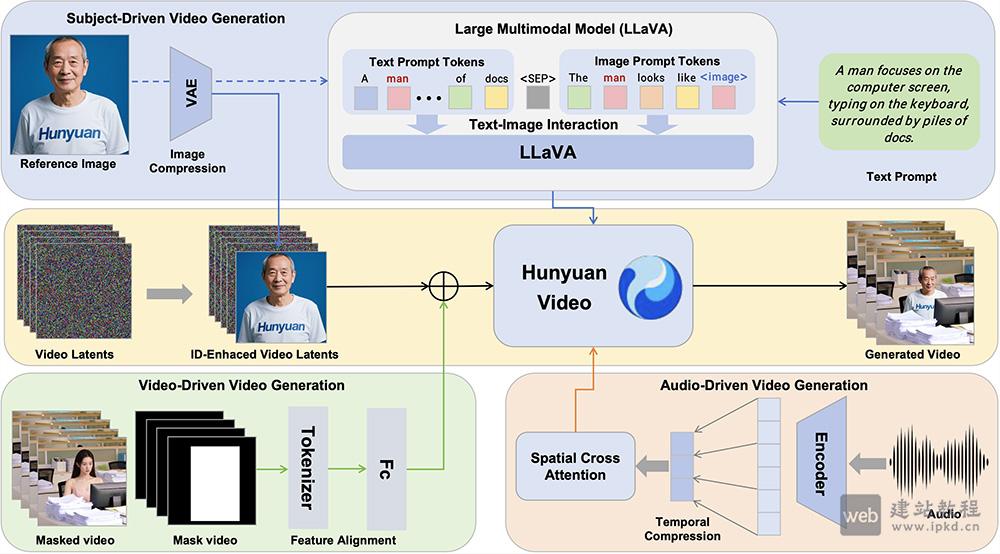
HunyuanCustom是一款多模态定制视频生成框架,可根据用户自定义条件,精准生成特定主题的定制化视频。该框架在人物身份一致性上表现突出,全面支持文本、图像、音频、视频多模态输入,适配虚拟人广告制作、个性化视频编辑等多元应用场景,为创作者提供高效的视频定制解决方案。
HunyuanCustom功能特点:
1、全维度多模态输入:
全面支持文本、图像、音频、视频四种输入形式,灵活适配各类定制化视频生成需求。
2、精准身份一致性:
通过图像ID增强模块与时间级联技术,全程保持视频中主体的身份、特征一致性,无违和感。
3、音频驱动动态生成:
深度结合音频输入,驱动视频中的角色完成同步的语音对话与动作表现,还原真实交互。
4、视频对象智能替换:
支持在原有视频中替换指定对象,替换后主体与给定图像特征一致,画面融合度高。
5、单/多主题灵活适配:
可满足单一主体或多个主体的视频生成需求,适配多角色场景创作。
6、多场景拓展应用:
可广泛应用于虚拟试衣、虚拟人广告、唱歌头像、个性化视频制作等多种场景。
7、高质量逼真生成:
相较传统方法,生成视频的真实感更强,文本描述与视频内容的对齐度更高。
8、多GPU并行推理:
支持在多个GPU上进行高效并行推理,大幅提升视频生成速度,满足高效创作需求。
HunyuanCustom使用场景示例:
1、虚拟人广告制作:
上传虚拟人图像与广告音频,通过音频驱动角色完成对话与动作,快速生成虚拟人广告视频。
2、个性化视频编辑:
在已有视频中替换指定角色,保持画面融合度与身份一致性,实现个性化视频修改。
3、创意内容制作:
创建虚拟唱歌头像,结合指定音乐音频,生成同步表演音乐作品的动态视频内容。
HunyuanCustom使用教程:
1、克隆HunyuanCustom官方代码库,获取项目基础开发文件。
2、安装项目所需依赖项,包括PyTorch及其他配套开发库。
3、下载官方预训练模型,按要求完成环境变量配置。
4、根据生成需求,准备好对应的输入文件(图像、音频、视频等)。
5、通过命令行运行生成脚本,明确指定输入文件路径与自定义生成条件。
6、等待模型完成推理生成,结束后查看视频输出结果。
7、根据生成效果,调整输入内容或模型参数,优化视频生成质量。
相关阅读文章
PixVerse V6模型官网 - 爱诗科技全新一代AI视频生成模型
Solaris多人视频模型官网入口,累计收集1260万帧多人游戏标注数据
InternVL-U模型使用入口,4B参数轻量化统一多模态模型
AIReel官网使用入口,一站式AI影片生成器文字、图片即刻转影片
HY-WU模型使用入口,腾讯混元推出的新一代功能性神经记忆框架
上面是“HunyuanCustom:支持文本、图像、音频、视频多模态输入的多模态定制视频生成框架”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://ipkd.cn/webs_30294.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!