openPangu-VL-7B是华为推出的开源多模态大模型,深度适配昇腾硬件架构,融合强大的语言理解与视觉分析能力,兼具高精度视觉定位、智能OCR识别等核心功能,可高效处理图像、文档、短视频等多类型任务。针对昇腾芯片的深度优化,让模型在720P图像推理时时延仅160毫秒,性能表现卓越,完美适配端侧部署与个人开发者的轻量化应用需求。其创新的视觉编码器与训练策略,更在多模态任务中展现出优异效果,为昇腾生态注入全新动力,助力开发者解锁更多场景化应用。
openPangu-VL-7B核心功能:
1、视觉定位与精准计数:
可在复杂画面中精准识别目标物体的位置信息并完成计数,例如在蔬果混放场景中快速定位所有樱桃番茄并统计数量,满足工业检测、零售盘点等精准识别需求。
2、智能文档理解与OCR:
支持将文档截图、扫描件一键转换为结构化Markdown格式,不仅能精准识别文本内容,更可解析图表数据,大幅提升文档数字化、信息提取的效率。
3、通用视觉问答(VQA):
针对上传的图像内容,可快速理解并回答各类相关问题,包括描述画面场景、解读细节特征、分析物体关系等,为教育答疑、信息查询提供智能支撑。
4、短视频内容深度解析:
具备短视频内容理解能力,可自动提取视频中的核心信息,生成内容摘要,或辅助完成内容审核,助力高效管理短视频素材库。
5、多模态任务灵活适配:
全面支持视觉推理、多图对比理解等复杂任务,可根据不同场景需求灵活调用能力,适配端侧、边缘计算等多元部署环境。
openPangu-VL-7B技术原理:
1、昇腾硬件深度适配架构:
专为昇腾芯片设计的原生模型架构,搭配定制化视觉编码器,相较传统编码器吞吐量提升15%,显著增强推理性能,充分释放硬件算力潜力。
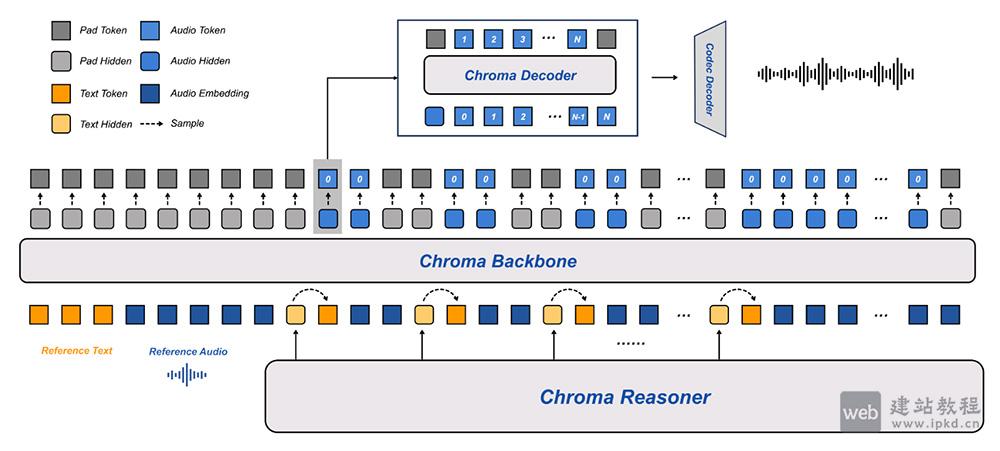
2、创新分层注意力视觉编码器:
融合22层窗口注意力与4层全注意力机制,强化细粒度视觉特征捕捉能力;同时采用多标签对比学习框架,为高精度视觉定位任务奠定坚实基础。
3、混合损失函数优化方案:
创新采用“加权逐样本损失+逐令牌损失”的混合损失设计,有效解决不同长度样本的学习不均衡问题,大幅提升模型的泛化能力与任务适应性。
4、带填充定位数据格式:
引入000-999千分位带填充相对坐标表示法,简化模型对目标位置的学习逻辑,降低定位任务难度,进一步提升计数与定位的精度和效率。
5、大规模无突刺集群预训练:
完成3T+tokens的大规模长稳训练,训练过程无性能突刺,不仅提升了模型的通用性,更为开发者提供了基于昇腾集群进行大模型训练的实践参考。
openPangu-VL-7B应用场景:
1、智能文档数字化处理:
快速将纸质文档扫描件、电子文档截图转换为可编辑的Markdown格式,自动提取文本与图表信息,适用于企业办公、政务处理等场景,节省人工录入时间。
2、视觉问答智能交互:
嵌入教育、客服等系统,用户上传图片即可提问,模型快速解答画面相关问题,例如识别文物特征、解读实验装置,提升信息查询的便捷性。
3、工业与零售精准检测:
在工业产线中定位并计数零部件,检测产品缺陷;在零售场景中盘点货架商品数量,实现库存的智能化管理,提升生产与运营效率。
4、短视频内容高效管理:
应用于短视频平台或内容库,自动提取视频关键信息生成摘要,辅助内容审核与分类,帮助运营者快速筛选优质内容。
5、多模态智能客服:
结合用户上传的商品图片、故障截图等视觉信息,精准理解咨询需求,提供更贴合实际的解决方案,提升客服响应的准确性与用户体验。
相关阅读文章
Mistral Small 4模型使用入口,Mistral AI 开源的多模态大模型
Fun-CineForge模型使用入口,通义实验室开源的影视级多模态配音大模型
InternVL-U多模态模型使用入口,上海AI实验室正式推出,仅40亿参数的轻量级模型
ZUNA是一款仅3.8亿参数的轻量化设计的开源脑电图(EEG)基础模型
上面是“openPangu-VL-7B:华为开源昇腾原生多模态大模型,端侧高效处理视觉语言任务”的全面内容,想了解更多关于 AI项目和框架 内容,请继续关注web建站教程。
当前网址:https://ipkd.cn/webs_26325.html
声明:本站提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请发送到邮箱:admin@ipkd.cn,我们会在看到邮件的第一时间内为您处理!