音频多模态模型
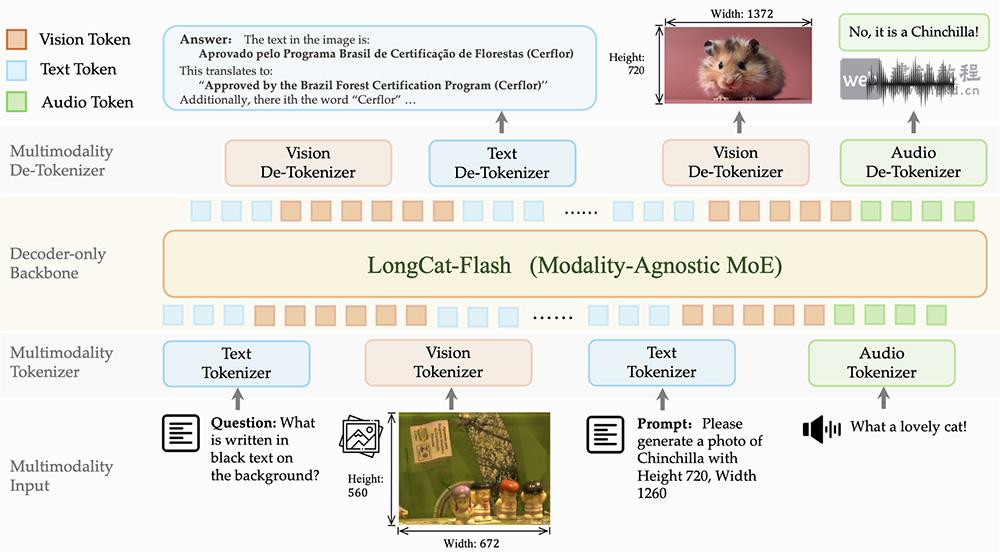
- LongCat-Next多模态模型 - 美团龙猫团队推出支持100万Token超长文本处理
LongCat-Next是美团龙猫团队(Meituan LongCat)推出的新一代多模态模型,模型通过智能评估模块重要性,将50%低重要模块替换为流式稀疏注意力,构建全局与局部交错的ZigZag结构,实现1M超长上下文、解码速度提升10倍、算力节省30%、硬件利用率翻倍,并提供Flash-Exp与Flash-Lite双版本,长文本任务表现超越Qwen-3。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
- Ming-omni-tts音频生成模型官网使用入口,优于SeedTTS、GLM-TTS
Ming-omni-tts模型通过统一连续音频Tokenizer与Diffusion Transformer架构,以12.5Hz帧率处理多模态音频,并借助「Patch-by-Patch」压缩策略将LLM推理帧率降至3.1Hz,在保证高音质的同时大幅降低延迟。

- Ming-UniAudio:蚂蚁集团推出的开源音频多模态大模型
Ming-UniAudio构建了端到端语音语言模型,精准平衡语音生成与语义理解性能;搭配扩散头技术,保障语音合成的高自然度与高还原度。尤为突出的是,模型首创指令引导的自由形式语音编辑框架,支持复杂的语义与声学修改,无需手动标定编辑区域,大幅降低操作门槛。






