Z-Image
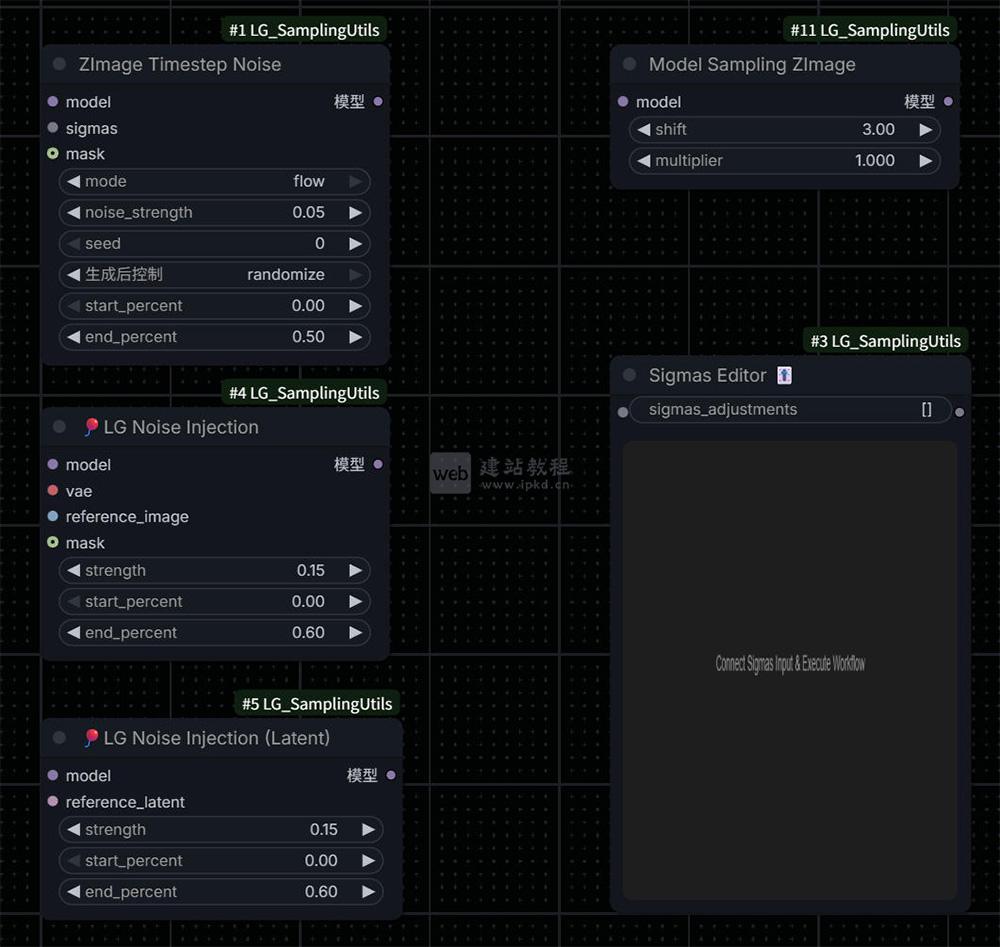
- ComfyUI-LG_SamplingUtils插件安装入口,一套专业采样增强工具
ComfyUI-LG_SamplingUtils是由开发者LAOGOU-666为ComfyUI量身打造的专业采样增强工具集,核心聚焦于提升ZImage、Lumina2、AuraFlow等Flow Matching架构模型的生成可控性与细节表现力。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
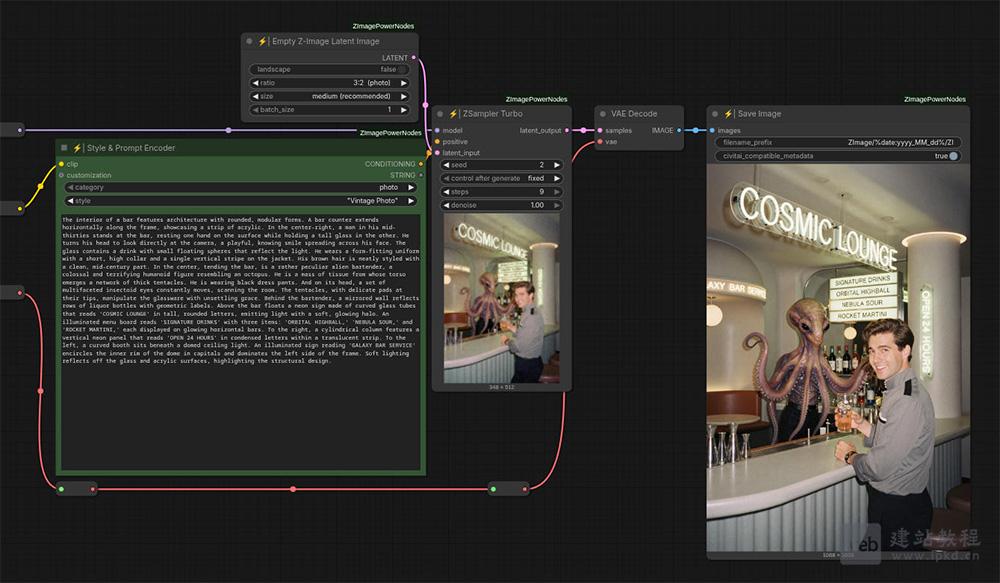
- ComfyUI-ZImagePowerNodes插件安装入口,专为Z-Image打造的ComfyUI自定义节点集
ComfyUI-ZImagePowerNodes是由martin-rizzo专为Z-Image打造的ComfyUI自定义节点集,源自作者实战“Amazing Z-Image Workflow”的工程经验,专注提升生成效率、画面控制力与图像画质。
- ComfyUI Z-Image I2L插件安装入口,ComfyUI自定义节点套件
ComfyUI Z-Image I2L核心优势是无需传统训练,仅需少量参考图即可快速生成专属LoRA,大幅降低制作门槛;输出格式标准化,可直接适配ComfyUI现有LoRA节点,集成性强;硬件上建议24GB+显存的GPU,避免运行时内存溢出。
- ComfyUI DiffSynth Studio Wrapper插件GitHub官网使用入口
ComfyUI DiffSynth Studio Wrapper是一款轻量级自定义节点封装器,核心目标是将DiffSynth-Studio的Z-Image I2L功能,无缝嵌入ComfyUI可视化工作流。借助该节点,用户无需进行外部模型训练或微调,即可直接从参考图像快速生成临时LoRA,并立即应用于新图像采样,高效实现风格、角色的精准迁移与视觉一致性保持。
- ComfyUI-CacheDiT模型安装入口,为ComfyUI设计的DiT模型一键加速插件
ComfyUI-CacheDiT是专为ComfyUI设计的DiT模型一键加速插件,通过智能缓存技术,为Z-Image、Qwen-Image、LTX‑2等主流DiT模型提供1.4–2.0倍推理加速,且几乎不损失图像与视频生成质量。插件零配置、开箱即用,完美解决DiT模型推理慢的痛点,让新手也能轻松获得高效生成体验。
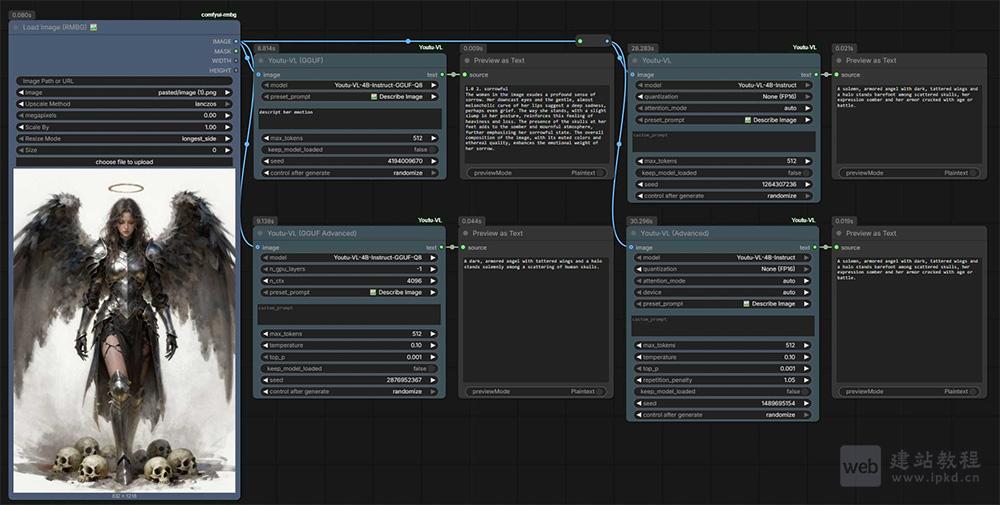
- ComfyUI-Youtu-VL插件安装入口,腾讯Youtu-VL视觉语言模型ComfyUI专属节点
ComfyUI-Youtu-VL插件是专为腾讯40亿参数轻量级视觉语言模型(Youtu-VL)打造的ComfyUI自定义节点插件,适配Youtu-VL模型的全量视觉任务,包括视觉定位、图像分割、深度估计、姿态估计等。
- ComfyUI Prompt Helper插件安装入口,Qwen3专属图像提示词优化工具
ComfyUI Prompt Helper的核心亮点的是对Qwen3-4B-Z-Image-Engineer模型的深度集成,专为Z-Image、Qwen Image等当前主流图像模型优化提示词结构,核心聚焦正向约束强化、纹理细节补充、电影级相机参数适配,帮用户快速将简单描述转化为高密度、结构化的专业提示词,大幅提升图像生成精度与质感,无缝适配ComfyUI原生工作流。