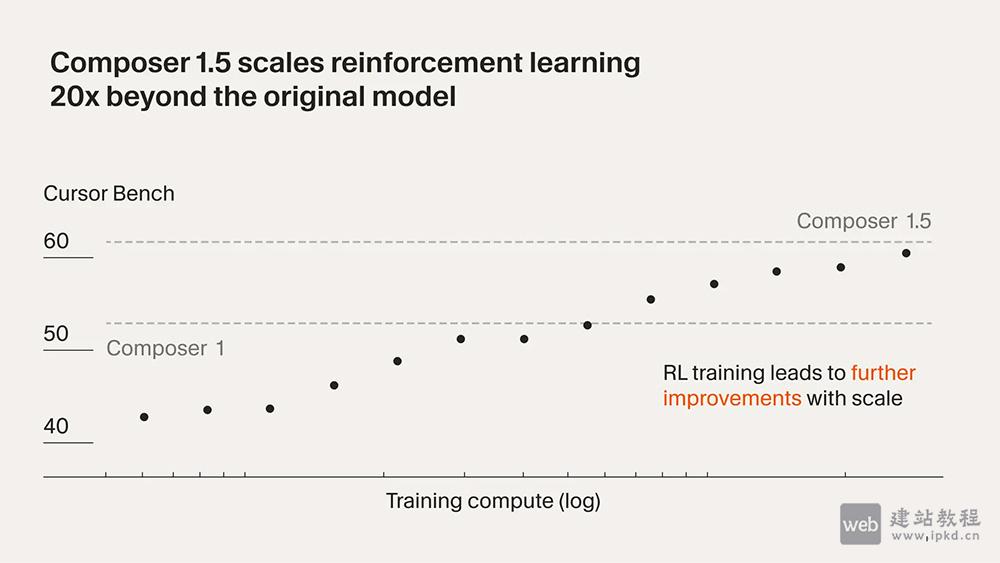
端到端大模型
- Qianfan-OCR模型使用入口,基于4B参数视觉语言架构,将文档解析、版面分析、文字识别与语义理解融为一体
Qianfan-OCR是百度千帆推出的端到端文档智能模型,模型在OmniDocBench v1.5评测中以93.12分位列端到端模型第一,通过Layout-as-Thought机制实现版面结构显式建模,支持复杂表格与图表理解,已开源且单卡A100可高效部署。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- Qwen2.5-Omni:阿里千问专为全方位多模态感知打造的新一代端到端多模态旗舰模型
Qwen2.5-Omni是阿里云通义千问的新一代端到端多模态旗舰模型,支持文本/图像/音频/视频全输入,可同步输出文本+自然语音,性能超越同规模单模态模型且已全平台开源。

- MOVA模型:中国首个高性能开源音视频端到端生成模型
MOVA是上海创智学院OpenMOSS团队与模思智能联合推出的中国首个高性能开源音视频端到端生成模型。拥有320亿参数,可同步生成长达8秒、720p分辨率的视频与配套音频,在电影级口型同步、环境音效契合度上表现卓越。
- Chroma 1.0:FlashLabs推出的首款开源实时端到端语音对话模型
Chroma 1.0是FlashLabs推出的首款开源实时端到端语音对话模型,该模型创新采用语音理解与生成紧密耦合架构,搭配1:2文本-音频token调度策略,可达成亚秒级输出;仅需几秒参考音频,就能精准复刻说话人音色,speaker相似度较人类基线提升10.96%。
- HunyuanOCR:腾讯混元推出的开源轻量级端到端OCR视觉语言模型
HunyuanOCR是腾讯混元团队推出的开源端到端OCR视觉语言模型,其功能覆盖文本检测与识别、复杂文档解析、开放字段信息抽取、视频字幕抽取等经典OCR任务,同时支持端到端拍照翻译与文档问答,为多场景文本处理提供一站式解决方案。

- FunAudio-ASR:阿里达摩院出品,企业级语音识别痛点的端到端大模型
FunAudio-ASR是阿里巴巴达摩院研发的端到端语音识别大模型,聚焦企业落地场景中的核心痛点,通过创新的Context增强模块,从根源上优化了语音识别领域的“幻觉”“串语种”等行业难题。

- Qwen3-Omni:阿里通义团队推出业界首个原生端到端全模态AI模型
Qwen3-Omni支持119种语言文本交互、19种语音理解语言及10种语音生成语言,轻松覆盖全球主流语种,满足跨地域业务需求。响应速度更实现突破性优化,纯模型端到端音频对话延迟低至211ms,视频对话延迟低至507ms,搭配长达30分钟的长音频理解能力,为实时交互场景提供流畅体验。
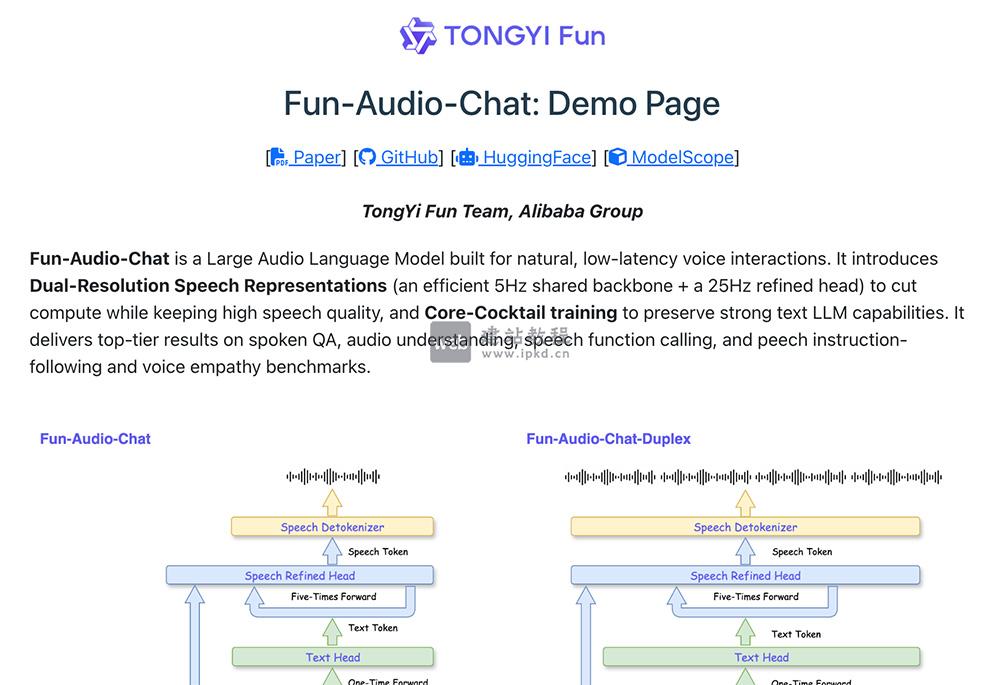
- Fun-Audio-Chat:阿里云通义百聆团队新一代端到端的开源语音交互模型
开源的Fun-Audio-Chat-8B在语音对话、情感识别等核心任务上表现突出,综合性能超越GLM4-Voice等同尺寸竞品,现已落地智能客服、情感陪伴等多元场景,开发者可通过ModelScope、HuggingFace平台免费下载使用。