HuggingFace模型库

- daVinci-MagiHuman音视频生成模型 - 模型采用150亿参数的单流Transformer架构
daVinci-MagiHuman是由上海创智学院GAIR实验室与Sand.ai联合开源的多模态统一生成模型。模型采用15B参数单流Transformer架构,统一建模文本、视频、音频三大模态,无需跨注意力机制。

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- DataChef模型 - 上海AI Lab联合复旦大学开源的AI数据配方生成模型
DataChef是由上海人工智能实验室(书生·浦语团队)与复旦大学联合开源的AI数据配方生成模型,可通过强化学习自动构建适配大模型任务的完整数据处理流水线,自动输出包含数据选择、清洗、合成、配比等环节的可执行代码。

- Nemotron-Cascade 2模型官网 - 英伟达正式开源的MoE混合专家模型,总参数量达30B
Nemotron-Cascade 2是英伟达正式开源的混合专家模型(MoE),总参数量达30B,而激活参数仅3B,实现了“轻体量”与“高性能”的完美平衡。尽管体量轻巧,它却在硬核推理领域展现出惊人爆发力。
- Hugging Face模型库官网入口,AI模型的GitHub
Hugging Face是全球最大的开源人工智能社区之一,通常被称为“AI模型的GitHub”。它汇集了超过30万个公开可用的预训练模型和5万个数据集,涵盖了自然语言处理(NLP)、计算机视觉(CV)、语音识别(ASR)等多个领域。

- Hypernova-60B-2602模型,Multiverse发布的免费开源压缩大模型
Hypernova-60B-2602是西班牙准独角兽企业Multiverse发布的免费开源压缩大模型,基于OpenAI开源模型深度优化,现已在Hugging Face面向全球开发者免费开放。依托自研CompactifAI压缩技术,模型体积缩减近50%,性能持平甚至超越原始模型,部分基准测试超越Mistral AI旗舰模型,实现“轻量化、高性能、低成本”部署。

- Voxtral Mini 4B Realtime 2602:Mistral AI正式开源的实时流式语音识别模型
Voxtral-Mini-4B-Realtime-2602是Mistral AI正式开源的实时流式语音识别模型,仅40亿参数,即可在保持高精度的前提下,实现500ms以内超低延迟,并原生支持中文等13种语言。
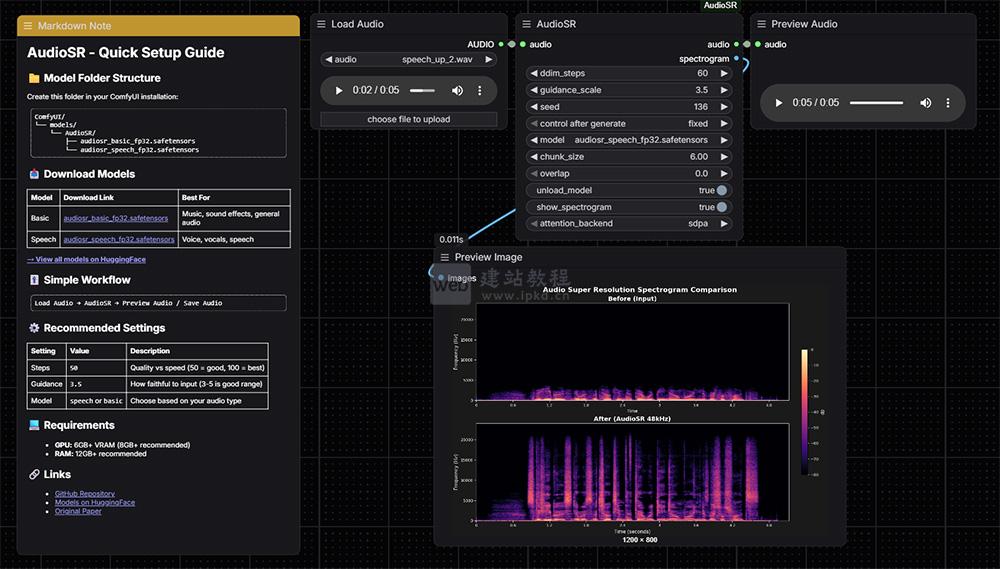
- ComfyUI AudioSR插件安装入口,ComfyUI原生音频超分辨率增强节点
ComfyUI AudioSR是专为ComfyUI打造的原生音频超分辨率处理节点,基于先进的潜在扩散模型AudioSR研发,核心能力是将任意低质量音频(低采样率、低码率)上采样至48kHz标准音质,同时精准增强高频细节、修复压缩失真问题,实现音频清晰度、饱满度的显著提升,完美适配ComfyUI音频处理工作流。

- JoyAI-LLM-Flash模型使用入口,京东AI开源的最新大语言模型
JoyAI-LLM-Flash是京东在Hugging Face正式开源的最新大语言模型,该模型采用混合专家(MoE)架构,总参数达480亿,而每次推理仅激活30亿参数,既能保持强大的模型能力,又能显著降低计算开销。
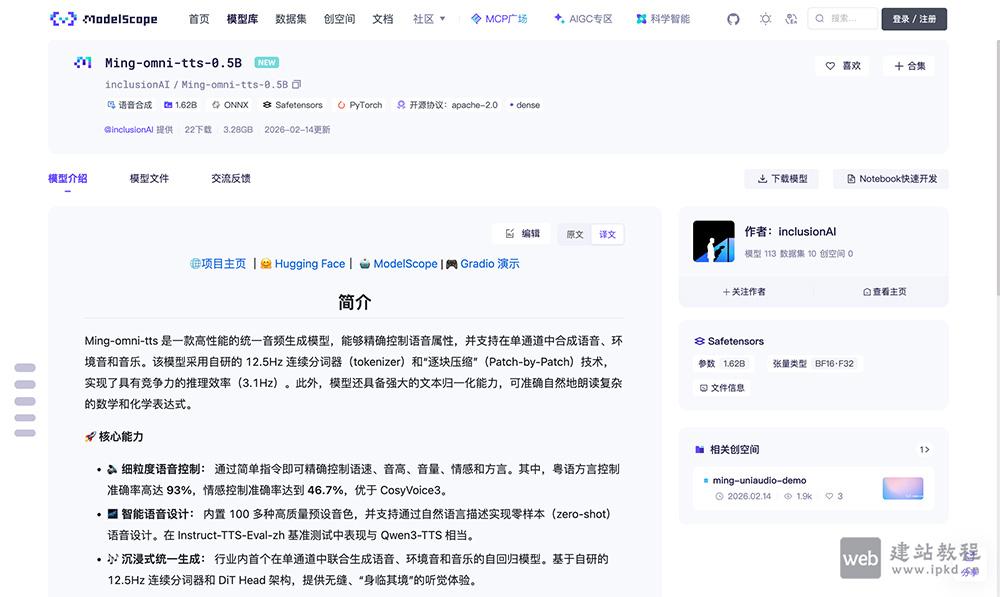
- Ming-omni-tts模型官网使用入口,大幅提升推理效率,推理帧率可低至3.1Hz,有效降低延迟
Ming-omni-tts核心依托团队自研技术,采用12.5Hz连续分词器,搭配逐块压缩技术,在坚守高音质输出的基础上,大幅提升推理效率,推理帧率可低至3.1Hz,有效降低延迟。同时,模型具备强劲的文本正则化能力,能够准确、自然地朗读复杂数学公式与化学方程式,完美适配专业内容播报、教育科普等对文本解析要求较高的场景。

- Ovis2.6-30B-A3B模型使用入口,阿里国际Ovis系列多模态大语言模型
Ovis2.6-30B-A3B核心升级为MoE架构,实现300亿总参数与仅30亿激活参数的平衡,兼顾大模型能力与小模型推理成本;MoE架构提效降本、64K长上下文+高清图像处理、主动式图像思考、强化的OCR/文档/图表理解。

- Nanbeige4.1-3B模型使用入口,30亿参数全能型开源模型,推理/对齐/智能体能力全拉满
Nanbeige4.1-3B以30亿小参数规模打破性能桎梏,通过多轮优化实现推理、对齐、智能体能力全方位提升;为小模型生态提供全能化发展新范式,保留轻量化部署优势的同时,具备比肩大模型的核心性能。
- Ring-2.5-1T模型魔塔使用入口,蚂蚁集团开源万亿参数思维模型
Ring-2.5-1T是蚂蚁集团推出的全球首个万亿参数混合线性注意力开源思维模型,核心实现“想得深、推得快、做得久”;模型开源且轻量化,重新定义万亿参数模型的性能边界,为通用人工智能体研发奠定关键基础。

- Ming‑Flash‑Omni 2.0模型使用入口,蚂蚁集团开源的全模态大模型
Ming-flash-omni-2.0是蚂蚁集团开源的SOTA全模态大模型,MoE架构兼顾性能与效率,核心实现图像/视频/音频/文本的统一理解与生成;核心适配智能教育、内容创作、文博数字化、实时交互娱乐、智能图像处理等场景。

- INTELLECT 3 MXFP4 MOE GGUF高性能混合专家推理模型
作为一款专为复杂场景设计的高性能大型语言模型,INTELLECT-3聚焦推理、数学、编码三大核心场景,原生支持工具调用与链式推理能力,旨在为用户提供一流的文本生成、多步骤问题解决能力,适配学术研究、软件开发、专业咨询等高端需求场景。

- Thedrummer Cydonia 24B V4.3 GGUF量化版大语言模型
该模型以TheDrummer/Cydonia-24B-v4.3为基础,通过llama.cpp工具将原始模型转换为Q8_0、Q6_K、Q4_K等多种量化格式,在显著压缩模型文件体积的同时,最大限度保留原版模型的核心质量,让这款24B参数的大模型能够在消费级硬件上高效运行,大幅降低大模型的部署与使用门槛,适配更多轻量化应用场景。