AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- Fun-AudioGen-VD模型使用入口,专注于专业声音设计与场景化音频生成
Fun-AudioGen-VD是阿里通义实验室语音团队自研的新一代语音生成大模型,专注于专业声音设计与场景化音频生成。模型支持自然语言FreeStyle自由指令生成,可一次性输出包含指定音色、情感、环境、空间、设备质感的完整音频。
- 音述AI官网使用入口,全球首个提供零门槛AI音乐创作社区
音述AI平台独创GETI风格定义法则,支持AI智能润色、作品交流、二次创作与价值变现,并针对中文语言习惯与文化深度优化,原生支持国风、C-pop等本土音乐风格,让技术真正服务于人文表达。
- PoseCut官网使用入口,内置30+专业级AI工具
PoseCut内置30+专业级AI工具,覆盖像素级文生图、电影级视频生成、智能抠图、换装、风格迁移等全场景能力,所有输出均按专业影视、广告、设计标准制作,确保高质量视觉效果。
- AdsTurbo官网使用入口,Sora 2提供技术支持的AI视频广告生成工具
AdsTurbo是由Sora 2提供技术支持的AI视频广告生成工具,专为电商、增长团队与绩效营销人员打造,解决传统广告制作繁琐、低效、成本高的痛点,实现极速产出、高点击率、高ROAS的视频广告。
- QuiverAI官网使用入口,面向设计师的AI矢量图形创作工具
QuiverAI是一款专业AI设计工具,专为设计师打造,用于生成、编辑、动画化可编辑SVG矢量资源。它以更高效率、更强创意表达、更精细的控制能力,赋能品牌、产品、营销全流程设计工作流,让设计师与开发者都能快速产出高质量、可商用的矢量图形。
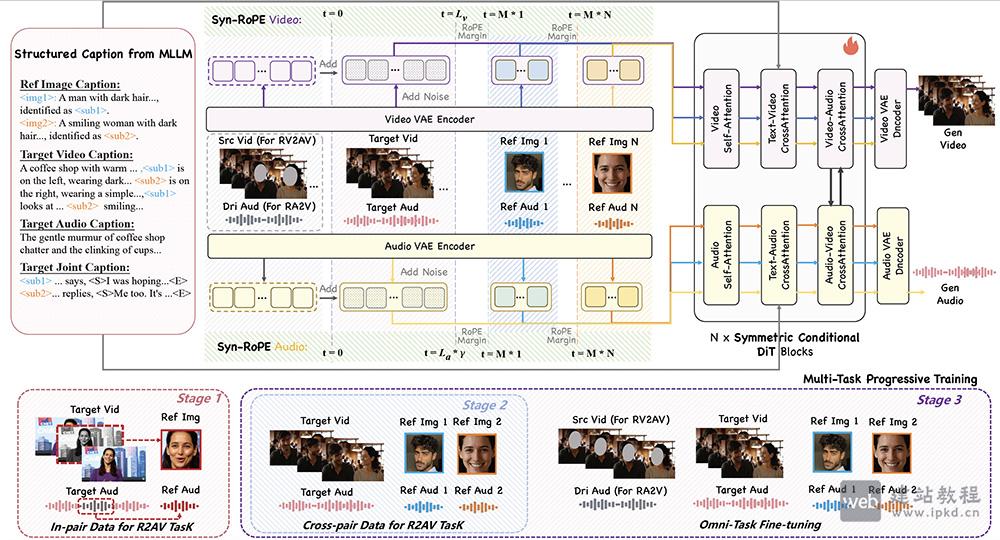
- DreamID-Omni虚拟数字人模型,清华 × 字节跳动统一可控以人为中心音视频生成框架
DreamID-Omni是由清华大学与字节跳动联合研发的统一、可控、以人为中心的音视频生成框架。它打破传统AI视频工具任务割裂的局限,在单一模型内同时实现参考生成、视频编辑、音频驱动动画三大核心能力,多项指标超越主流商业闭源模型,实现了端到端统一架构的重大突破。
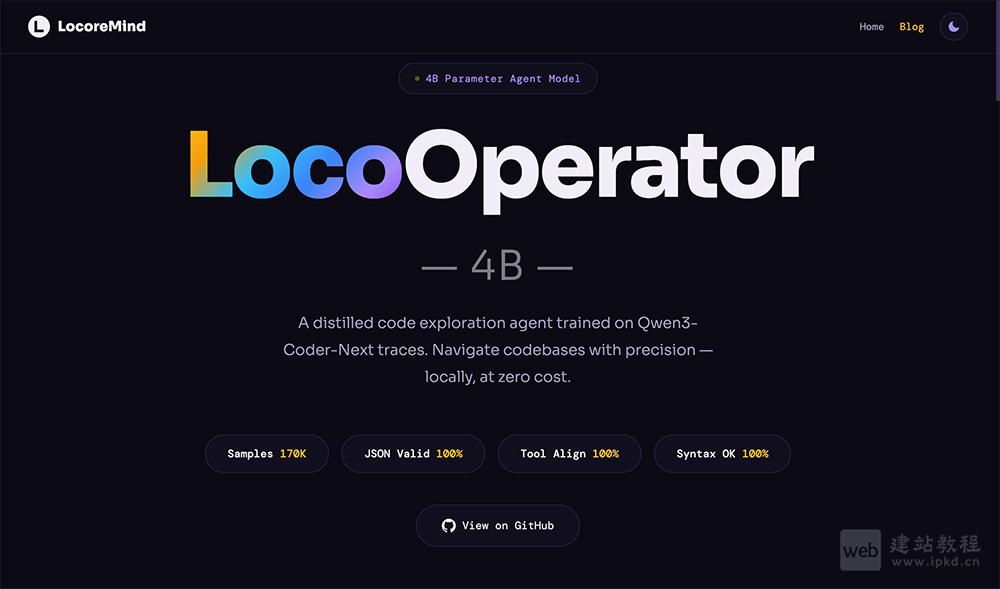
- LocoOperator-4B模型使用入口,4B参数轻量级本地代码探索智能体
LocoOperator-4B是LocoreMind开源的4B参数代码探索专用智能体,基于Qwen3-4B-Instruct经知识蒸馏自Qwen3-Coder-Next训练而成。定位为Claude Code等编程助手的本地化子智能体,专注处理代码库搜索、文件读取、目录遍历等探索类任务,实现零API成本运行。
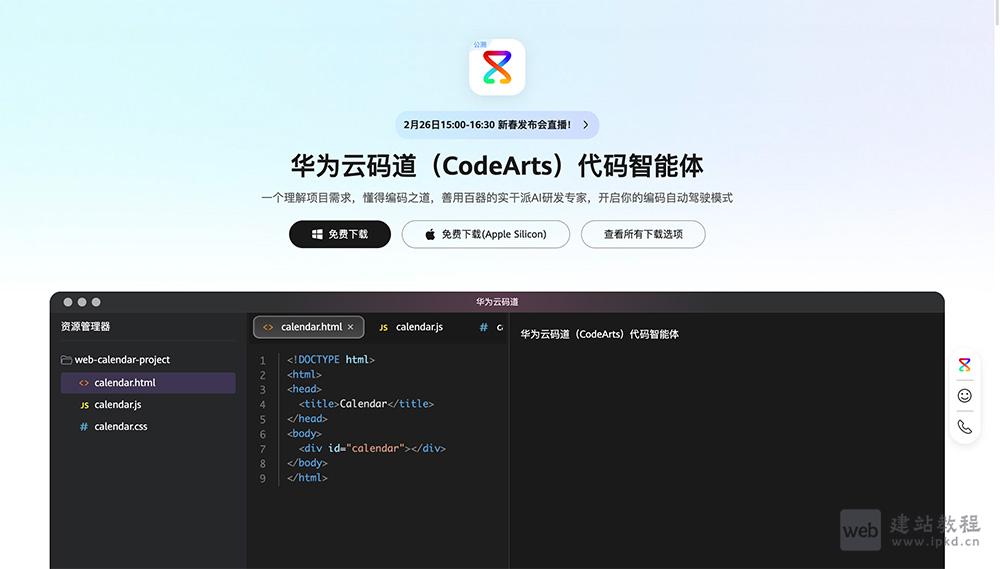
- 华为云码道(CodeArts)代码智能体官网使用入口
CodeArts Doer是华为推出的一站式AI智能研发平台,覆盖软件开发全生命周期,通过6大智能Agent实现需求、开发、测试、部署全流程自动化协作,大幅压缩研发周期、降低沟通成本与返工风险。平台深度融合华为多年工程化研发经验与海量研发数据,为开发者与团队提供“更快、更准、更稳”的智能化研发提效方案。
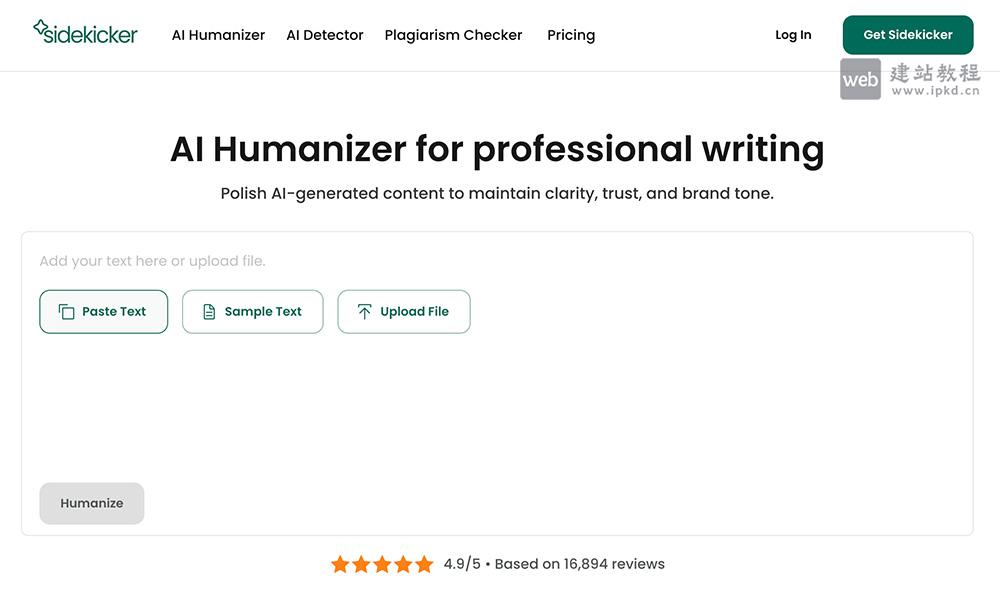
- AI Humanizer官网使用入口,Sidekicker旗下的专业AI文本自然化改写工具
AI Humanizer是Sidekicker旗下的专业写作辅助工具,专注将生硬、机械的AI生成内容,转化为自然流畅、专业得体、贴合品牌风格的人类语言,有效提升内容可信度、可读性与说服力,适用于文案、官网内容、报告、邮件等各类专业写作场景。
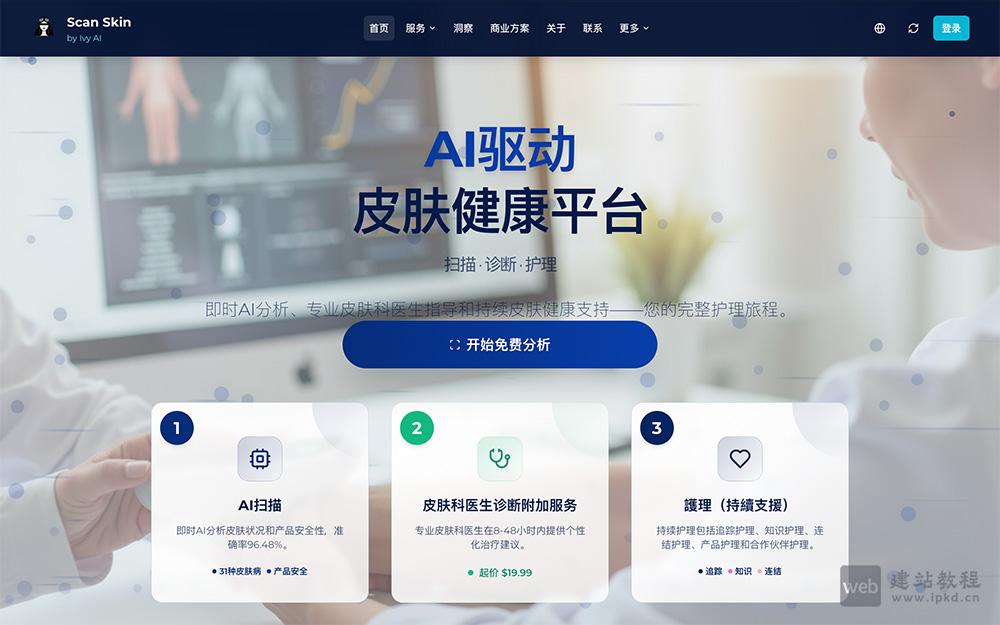
- ScanSkinAI官网使用入口,专业级全流程AI皮肤健康平台
ScanSkinAI是由Ivy AI Solutions Limited打造的专业级AI皮肤健康平台,依托先进AI技术,以96.48%的准确率精准检测31种皮肤病,提供从皮肤扫描、智能分析、专家诊断到长期护理的一站式服务,覆盖个人、患者、企业及医护人员全场景,价格灵活可按需选择,全方位满足不同人群的皮肤健康管理需求。

- Nano Banana 2模型使用入口,Google DeepMind新一代高精度图像生成模型
Nano Banana 2是由Google DeepMind推出的新一代图像生成模型,基于Gemini 3.1 Flash Imag架构,深度融合Gemini知识库与实时网络搜索能力,可精准还原真实场景、生成规范多语言文字,并支持强一致性角色与物品生成。
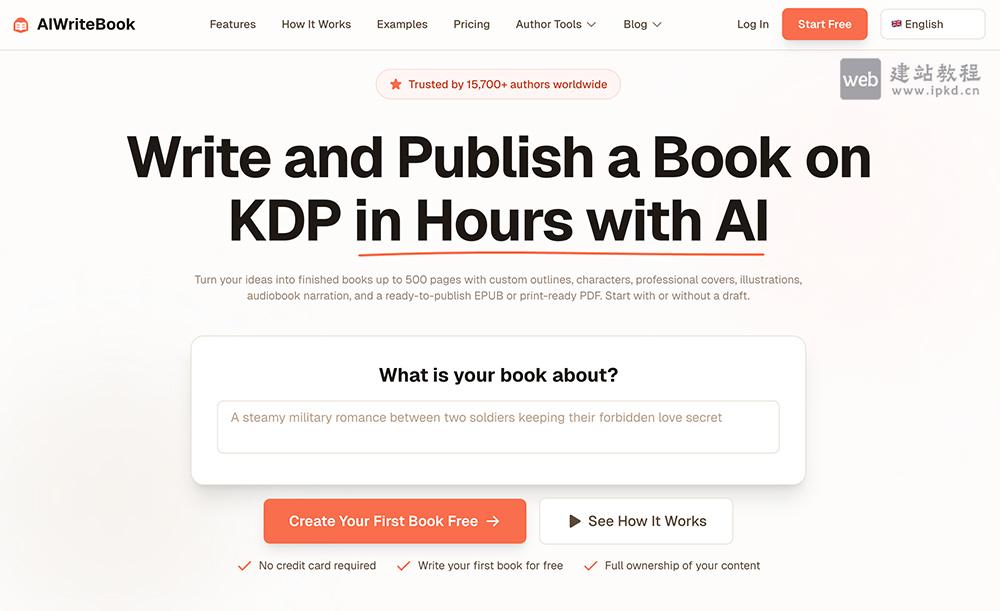
- AIWriteBook官网使用入口,专注书籍创作的AI智能写作辅助工具
AI Book Writer是一款专注书籍创作的AI智能写作辅助工具,通过人工智能技术全程助力写书流程,大幅降低创作门槛、节省时间与精力,让任何人都能快速完成一本完整作品。工具覆盖大纲生成→章节撰写→封面设计→有声书制作全流程。
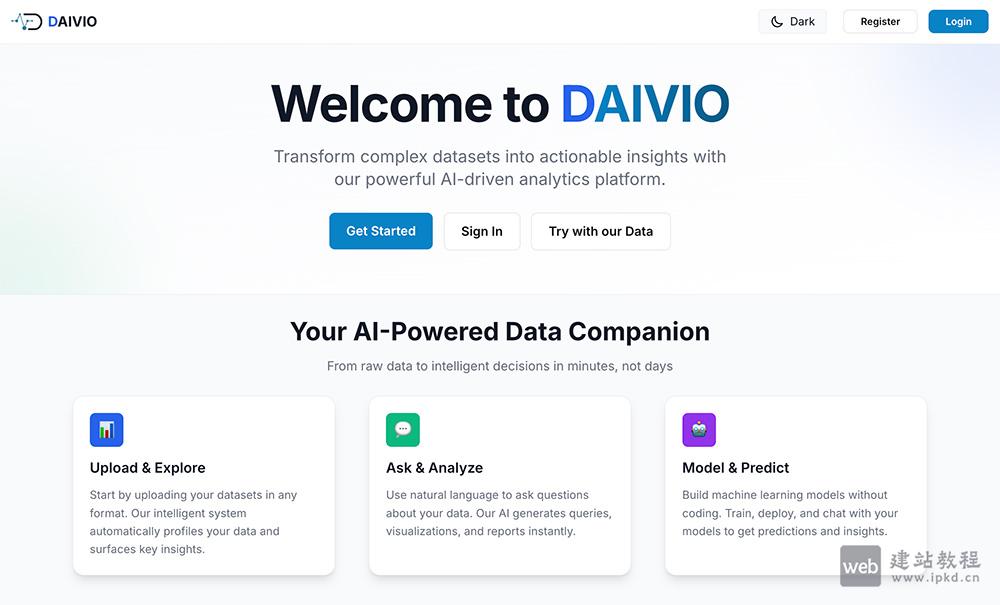
- Daivio官网使用入口,将复杂数据集转化为可落地的AI数据分析平台
DAIVIO是一款AI全自动高级数据分析平台,支持多格式数据、自然语言查询、零代码建模、交互式可视化,并提供企业级安全隐私保障,提供免费试用,专为分析师、数据科学家、企业决策者打造。
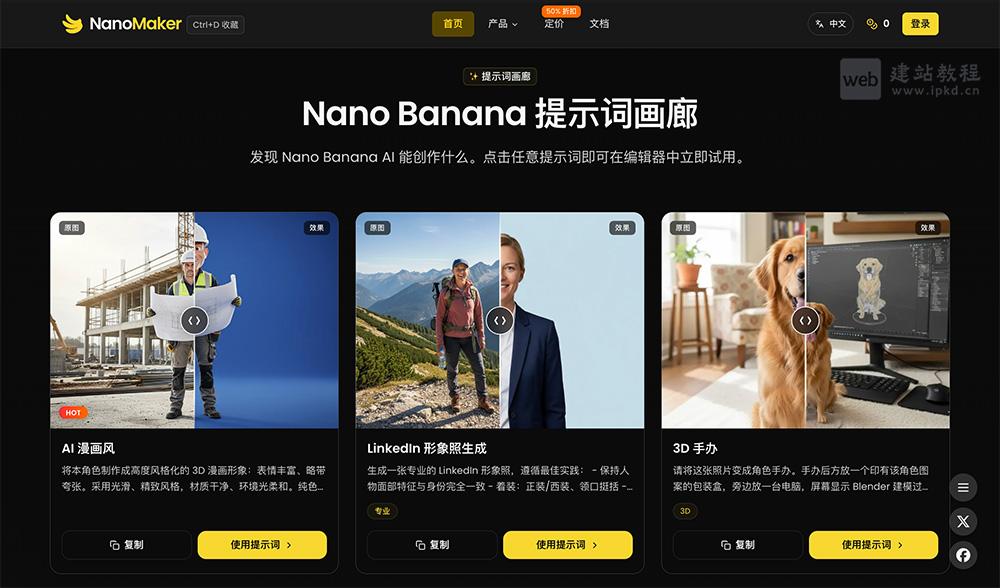
- NanoMaker AI官网使用入口,一站式AI创意创作平台(含Nano Banana Pro)
NanoMaker是一款综合性AI创意工具集,整合图像、视频、音乐、音频四大核心处理功能,内置Nano Banana Pro,汇聚全球顶级AI模型,采用单一订阅模式,为用户提供全场景创意解决方案。
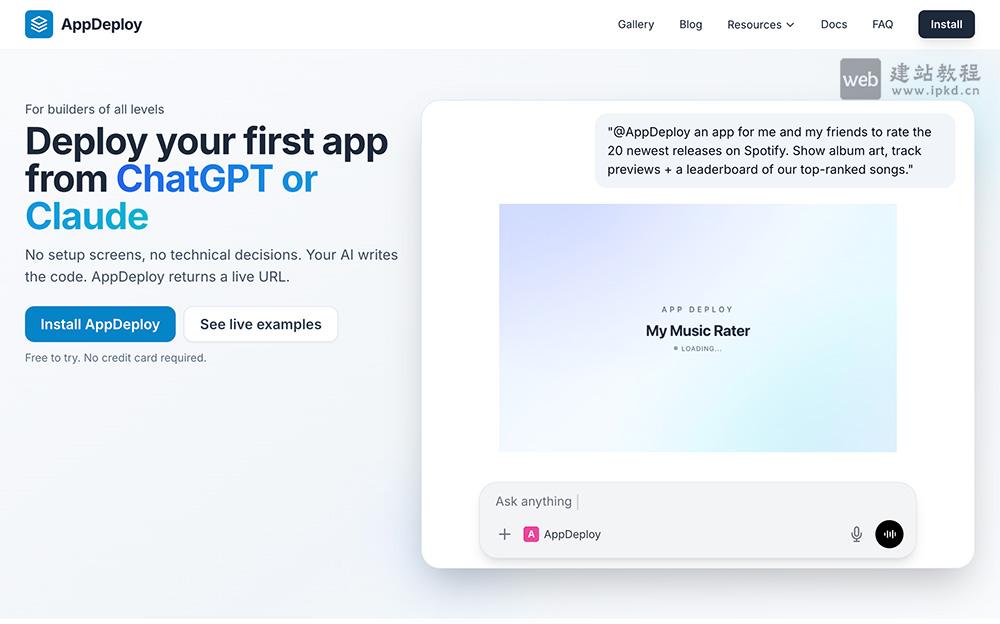
- AppDeploy官网使用入口,从ChatGPT/Claude对话直接部署应用的零门槛平台
AppDeploy是一个无需配置、纯对话式应用部署平台,支持直接从ChatGPT、Claude自然语言描述需求,让AI自动生成代码并一键上线,实时返回可访问的应用URL。它极大简化了应用构建与发布流程,让任何人都能快速把想法变成可运行的产品。平台提供免费试用,无需信用卡,面向所有开发者、创业者与创意人群。