AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
- IronClaw官网使用入口,NearAI团队推出的开源AI助手
IronClaw是OpenClaw的安全开源替代方案,它在NEAR AI云的加密飞地中运行。人工智能智能体确实能执行任务,但你的机密信息绝不会接触到大型语言模型。

- Steerling-8B模型使用入口,80亿参数规模,在1.35万亿Token语料上训练完成
Steerling-8B是由Guide Labs正式发布的全球首个具备内在可解释性的大语言模型。它的问世不仅是一款新模型的推出,更代表了AI架构设计从「事后归因、黑盒猜测」向「事前设计、全程可溯」的范式级突破,让模型生成的每一个Token都具备清晰、可追溯的依据。

- LFM2-24B-A2B模型使用入口,LiquidAI正式发布的LFM2家族模型
LFM2-24B‑A2B是LiquidAI正式发布的LFM2家族中规模最大的早期模型,采用稀疏混合专家架构,在端侧高性能大模型落地上实现关键突破。模型总参数达240亿,但推理时每个Token仅激活20亿参数,可完美运行在32GB内存的消费级设备上,让高性能大模型真正走向端侧部署。
- Qwen3.5系列重大更新:多款中型模型开源,性能与效率再攀行业新高
Qwen3.5中型模型家族以高效架构+原生多模态+全语言支持,正式开源Qwen3.5-35B-A3B、Qwen3.5-122B-A10B、Qwen3.5-27B三款中型模型,打造“性能强、成本低、易部署”的开源新标杆,全面覆盖从个人开发到企业级落地的全链路需求。
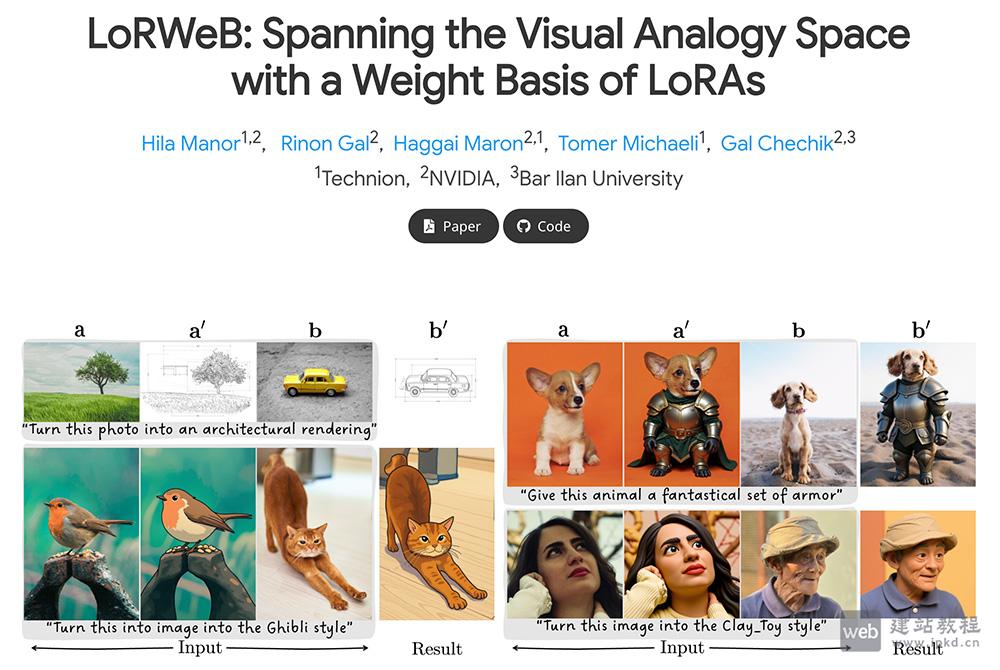
- LoRWeB官网使用入口,色列理工学院与NVIDIA研究团队联合推出的全新AI图像编辑技术
LoRWeB是由以色列理工学院与NVIDIA(英伟达)研究团队联合推出的全新 AI 图像编辑技术,突破传统文字指令限制,通过示例学习理解图像变换逻辑,并将变换效果迁移到新图片中,实现“举一反三”式智能修图。

- Grok 4.20模型使用入口,采用约3T参数的MoE架构,支持256K tokens超长上下文窗口
Grok 4.20是马斯克旗下xAI推出的新一代多智能体AI系统,核心搭载革命性「四Agent协作架构」,内置队长Grok、研究专家Harper、逻辑专家Benjamin及创意专家Lucas四大专业化智能体。

- FireRedASR2S模型使用入口,支持中文普通话+20余种方言、英语、中英混读、代码切换及歌词识别
FireRedASR2S是小红书Super Intelligence-AudioLab开源的工业级端到端语音识别模型,一站式集成ASR、VAD、语种识别、标点预测四大SOTA模块,实现从音频到可读文本的全链路高精度处理。
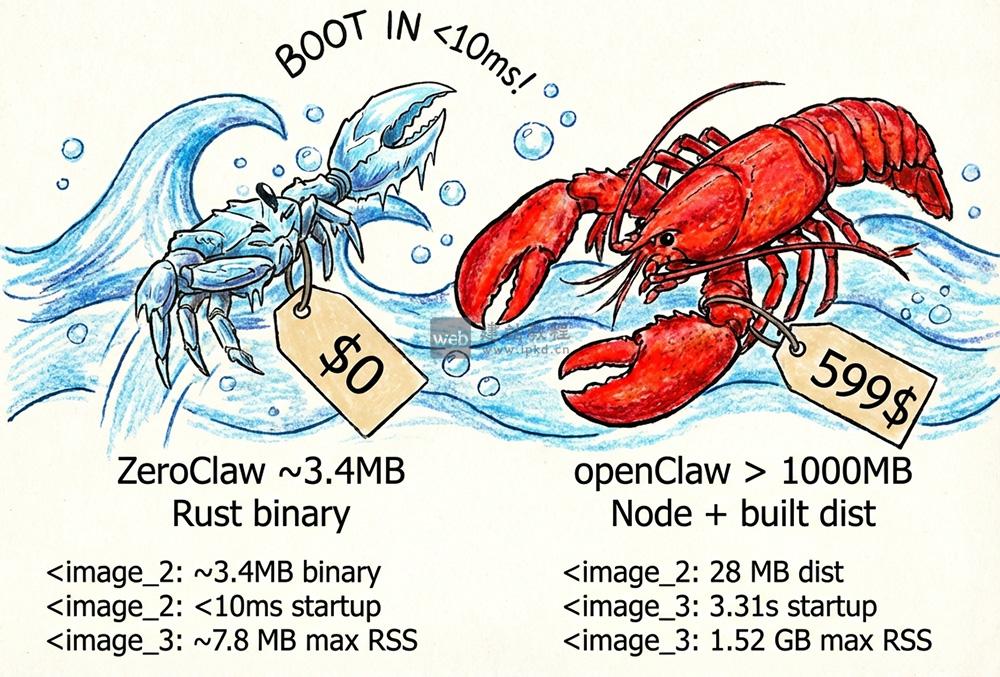
- ZeroClaw模型官网入口,轻量级生产级AI助手基础设施
ZeroClaw是一款基于Rust开发的轻量级AI助手基础设施,采用Trait驱动架构,将模型Provider、通信Channel、工具Tool、内存Memory等核心能力抽象为标准化可插拔接口,实现零厂商锁定——OpenAI、Claude、本地Ollama等模型,以及Telegram、Discord等通信渠道均可一键无缝切换。
- ZUNA是一款仅3.8亿参数的轻量化设计的开源脑电图(EEG)基础模型
ZUNA基于掩码扩散自编码器(Masked Diffusion Autoencoder)架构构建,在近200万通道小时的公开脑电图数据上完成大规模预训练,深度习得脑电信号的通用先验规律,实现对信号的理解式处理。
- MioCodec v2模型使用入口,用于高效口语语言建模的高保真神经音频编解码器
MioCodec v2是一款高效、轻量的专业编解码工具,聚焦音视频及数据编码解码核心需求,依托优化的底层架构设计,为各类编码解码任务提供稳定、高效的解决方案,填补轻量型专业编解码工具的场景空白,同时可灵活对接各类开发框架与终端设备,降低编解码技术的应用门槛。

- PicoClaw官网使用入口,支持Telegram、Discord等多平台接入
PicoClaw是Sipeed推出的超轻量级AI Agent助手,采用Go语言开发,专为低成本硬件量身打造。不同于本地运行大模型的方案,它以轻量客户端形式,通过API调用Claude、GPT、智谱GLM等云端模型,同时在本地高效实现文件操作、网页搜索、任务规划等核心Agent能力。
- Protenix-v1模型使用入口,开源生物分子结构预测的新标杆
Protenix-v1是字节跳动Seed团队开源的生物分子结构预测模型,首个在同等条件下(数据截止2021-09-30、相同模型规模和推理预算)性能达到甚至超越AlphaFold3的完全开源方案。

- ClawWork模型使用入口,HKUDS开源的AI Agent经济生存基准测试框架
ClawWork支持GPT-4o、Claude、Kimi等多模型同台竞技,并配备React实时仪表板用于监控Agent生存状态,为AI劳动力经济研究提供了首个“用进废退”的真实压力测试场景。

- Gemini 3.1 Pro:基于Gemini 3系列架构深度优化,是对Gemini 3 Deep Think能力的全面革新
Gemini 3.1 Pro定位为更强智能、更高性能的新一代基线模型,核心推理能力实现显著进化,尤其擅长处理逻辑严谨、步骤复杂、多环节推理的高难度任务。

- Voxtral Mini 4B Realtime 2602:Mistral AI正式开源的实时流式语音识别模型
Voxtral-Mini-4B-Realtime-2602是Mistral AI正式开源的实时流式语音识别模型,仅40亿参数,即可在保持高精度的前提下,实现500ms以内超低延迟,并原生支持中文等13种语言。