AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- KaniTTS2模型使用入口,NineNineSix正式开源的新一代TTS模型
KaniTTS2是AI初创公司NineNineSix正式开源的新一代文本转语音(TTS)模型,专为低延迟、高自然度的实时对话场景量身打造。该模型支持语音克隆、多语言输出,同时提供完整的从零预训练代码框架,助力开发者基于自有数据快速训练定制化TTS模型。

- Xiaomi-Robotics-0模型官网首页入口,小米开源的首代机器人VLA(视觉-语言-动作)大模型
Xiaomi-Robotics-0模型是小米开源的首代机器人VLA(视觉-语言-动作)大模型,搭载47亿参数,创新采用MoT混合架构——以Qwen3-VL多模态模型为“大脑”,负责解析视觉与语言指令、理解场景意图;以Diffusion Transformer(DiT)为“小脑”,专注生成高频平滑动作块。
- Ming-omni-tts模型官网使用入口,大幅提升推理效率,推理帧率可低至3.1Hz,有效降低延迟
Ming-omni-tts核心依托团队自研技术,采用12.5Hz连续分词器,搭配逐块压缩技术,在坚守高音质输出的基础上,大幅提升推理效率,推理帧率可低至3.1Hz,有效降低延迟。同时,模型具备强劲的文本正则化能力,能够准确、自然地朗读复杂数学公式与化学方程式,完美适配专业内容播报、教育科普等对文本解析要求较高的场景。
- Hibiki-Zero模型官网使用入口,30亿参数的同步语音到语音翻译模型
Hibiki-Zero继承其前身Hibiki的多流RQ-Transformer架构,采用仅解码器设计,核心依托流式神经音频编解码器Mimi,以12.5Hz恒定帧率,对源音频、目标音频,以及用于内部推理的“内心独白”文本流进行联合建模。这种一体化设计赋予模型持续处理输入语音流的能力,可同步输出连续的翻译音频及带时间戳的对应文本,完美适配实时交互场景。
- Seed2.0模型官网使用入口,字节跳动Seed团队推出的新一代通用Agent大模型家族
Seed 2.0是字节跳动Seed团队自研推出的新一代通用Agent大模型家族,由Pro/Lite/Mini三款通用模型与Code专用模型组成,全面升级多模态理解、长上下文处理与复杂任务执行能力,兼顾顶尖性能与普惠成本。

- Ovis2.6-30B-A3B模型使用入口,阿里国际Ovis系列多模态大语言模型
Ovis2.6-30B-A3B核心升级为MoE架构,实现300亿总参数与仅30亿激活参数的平衡,兼顾大模型能力与小模型推理成本;MoE架构提效降本、64K长上下文+高清图像处理、主动式图像思考、强化的OCR/文档/图表理解。

- FireRed-Image-Edit模型使用入口,小红书出品通用图像编辑模型,打破专业修图门槛
FireRed-Image-Edit核心优势是精准理解自然语言指令,实现高保真、视觉一致的全维度图像编辑,解决现有AI修图“改不准、易翻车、门槛高”的痛点;功能覆盖内容/风格/结构/文字四大维度,还支持虚拟试穿、老照片修复等特色玩法,适配日常修图、电商、创意创作等多场景。

- Nanbeige4.1-3B模型使用入口,30亿参数全能型开源模型,推理/对齐/智能体能力全拉满
Nanbeige4.1-3B以30亿小参数规模打破性能桎梏,通过多轮优化实现推理、对齐、智能体能力全方位提升;为小模型生态提供全能化发展新范式,保留轻量化部署优势的同时,具备比肩大模型的核心性能。
- Ring-2.5-1T模型魔塔使用入口,蚂蚁集团开源万亿参数思维模型
Ring-2.5-1T是蚂蚁集团推出的全球首个万亿参数混合线性注意力开源思维模型,核心实现“想得深、推得快、做得久”;模型开源且轻量化,重新定义万亿参数模型的性能边界,为通用人工智能体研发奠定关键基础。
- Seedream 5.0 Lite模型官网使用入口,字节跳动新一代AI图像创作模型
Seedream 5.0 Lite核心优势是多模态统一架构+实时联网检索,视觉推理精准、内容时效性强,支持风格迁移、高阶编辑等专业功能;可通过即梦AI、火山方舟、豆包App(内测)使用,覆盖办公、营销、影视、艺术、社交等全场景图像创作需求。
- GenPPT AI官网使用入口,10倍速制作+专业美化,适配商务/教育全场景
GenPPT AI核心优势是基于Claude/Opus 4实现10倍速PPT生成、智能排版美化、自动讲稿创作,大幅节省制作时间;适配商务人士、教育工作者、内容创作者三类人群,覆盖融资、教学、销售等多场景PPT制作需求。
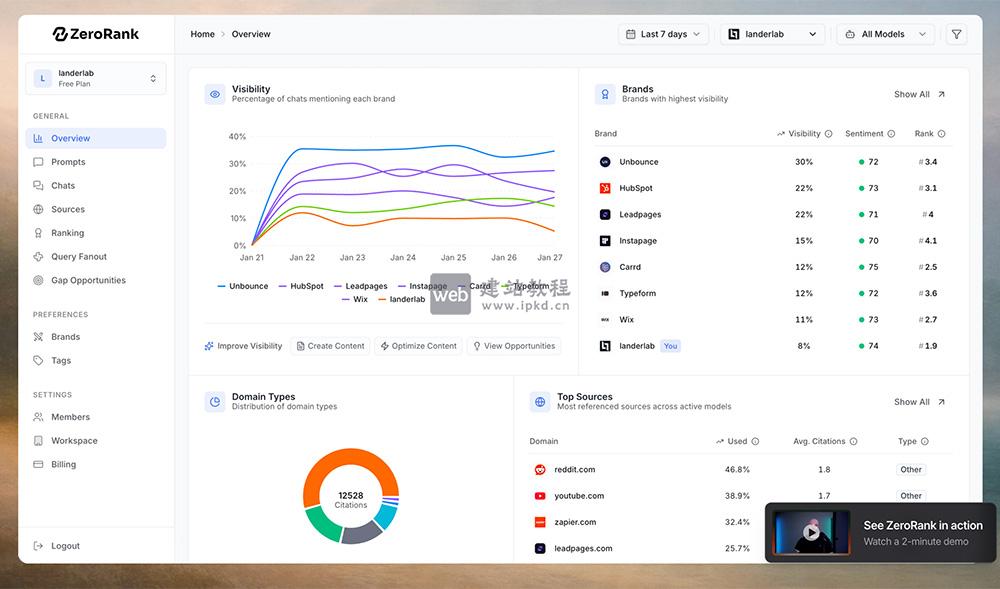
- ZeroRank AI官网使用入口,多模型追踪+数据化洞察,抢占AI搜索流量先机
ZeroRank AI核心价值是监测并优化企业在AI搜索中的品牌表现,支持多模型覆盖、竞品对比、内容策略优化,帮助企业抢占AI搜索流量先机;分Starter/Pro/Enterprise三档套餐,适配初创/中小/大型企业不同需求,年付最高省15%且提供免费试用。
- Candidate Search AI官网使用入口,招聘行业专属AI招聘工具
Candidately核心优势是自然语言搜索ATS候选人库(极速+精准)、免费AI简历生成,大幅降低招聘筛选与资料制作成本;操作流程极简(注册连ATS-自然语言搜索-使用增值功能-管理候选人),提供免费试用,显著提升招聘效率与体验。
- Seedream 5.0 AI模型官网使用入口,2K高保真+秒级生成,适配全场景创作需求
Seedream 5.0 AI基于第五代扩散变压器模型,核心优势为2K高保真画质、5-10秒极速生成、精准的文本/图像控制能力;支持文本生图、图生图编辑、多主题合成等全场景创作;操作流程极简,创作门槛低且商用适配性强。
- Seedance 3.0模型官网使用入口,字节跳动AI视频生成器
Seedance 3.0是字节跳动推出的低门槛AI视频生成器,核心优势为广播级画质、文本转视频、多风格创作,适配电商/网红/开发者等多人群;支持批量处理、无水印下载、API拓展等商用级功能,付费套餐限时50%折扣,性价比突出。