AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
- Ming-omni-tts音频生成模型官网使用入口,优于SeedTTS、GLM-TTS
Ming-omni-tts模型通过统一连续音频Tokenizer与Diffusion Transformer架构,以12.5Hz帧率处理多模态音频,并借助「Patch-by-Patch」压缩策略将LLM推理帧率降至3.1Hz,在保证高音质的同时大幅降低延迟。

- Lyria 3模型使用入口,30秒快速生成带歌词、伴奏与定制封面的完整原创音乐片段
Lyria 3是谷歌DeepMind研发的新一代AI音乐生成模型,现已原生集成到Gemini,支持文本、图片/视频多模态输入,30秒快速生成带歌词、伴奏与定制封面的完整原创音乐片段。目前处于测试阶段,面向全球18岁以上用户开放。

- DeepGen 1.0模型使用入口,浙江大学等联合推出的轻量级统一多模态模型,仅50亿参数
DeepGen 1.0是由中国科学技术大学、西湖大学与南加州大学等联合推出的轻量级统一多模态模型,仅50亿参数,却在通用图像生成、编辑及复杂逻辑理解任务中实现超越级表现,多项指标击败参数量为其3–16倍的国际顶级模型。

- BitDance模型使用入口,字节跳动正式开源的140亿参数离散自回归多模态基础模型
BitDance是字节跳动正式开源的140亿参数离散自回归多模态基础模型。凭借创新的二进制Token编码机制与并行扩散预测范式,模型在保持高分辨率、高保真画质的前提下,实现了颠覆性的生成速度,效率较传统自回归模型提升30倍以上,甚至超越多款主流扩散模型。

- Capybara模型使用入口,一款单一架构、全功能整合的全能型AI系统
Capybara一款单一架构、全功能整合的全能型AI系统,它以先进扩散模型与Transformer架构为核心底座,将文本到图像/视频生成、指令式精细编辑、上下文条件生成及关键帧传播等多元能力深度融合,打破传统AI任务需多模型、多接口切换的壁垒——无论是从零启动的创意生成。

- Tiny Aya模型使用入口,Cohere Labs正式发布的开源多语言模型
Tiny Aya系列是企业级AI独角兽Cohere旗下Cohere Labs正式发布的开源多语言模型,专为真实场景落地打造。该系列支持70余种语言,仅33.5亿参数,即可在笔记本电脑、智能手机等终端设备上流畅运行,且支持完全离线使用。
- Claude Sonnet 4.6模型官网入口, Anthropic全新推出的新一代AI模型
Sonnet 4.6突破性支持100万Token超长上下文窗口,单次请求即可轻松处理完整代码库或数十篇学术论文;创新引入“自适应思考”专属机制,能够根据任务复杂度动态调配推理资源,避免算力浪费。在OSWorld计算机使用基准测试中,其得分从4.5版本的61.4%飙升至72.5%,性能表现已趋近人类操作水平,适配更多复杂实用场景。

- JoyAI-LLM-Flash模型官网入口,京东开源的中型指令大模型
JoyAI-LLM-Flash是京东开源的中型指令大模型,模型创新性引入FiberPO优化框架——首次将纤维丛理论应用于强化学习,结合Muon优化器完成SFT、DPO及RL全阶段训练;同时搭载稠密多Token预测(MTP)技术,吞吐量较非MTP版本提升1.3-1.7倍。

- FireRed-Image-Edit模型官网入口,小红书Super Intelligence团队开源的通用图像编辑模型
FireRed-Image-Edit是小红书Super Intelligence团队开源的通用图像编辑模型,模型具备精准的指令遵循能力、高质量图像输出表现及出色的视觉一致性,尤其在文字风格保留方面优势突出,编辑效果可媲美主流闭源方案;同时在多个权威评测集上斩获SOTA成绩,广泛适配创意设计、电商内容创作等多元化场景。
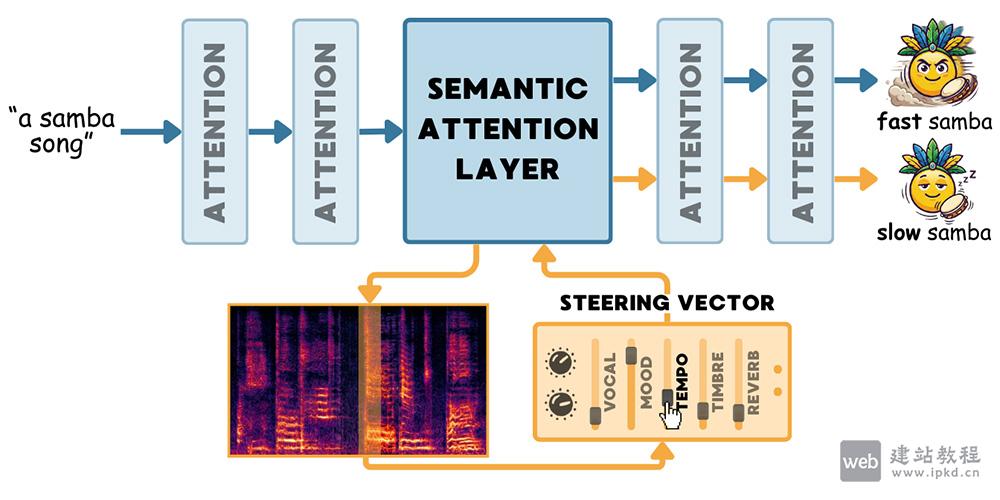
- TADA模型使用入口,通过激活引导微调音频扩散模型
TADA的核心目标是打开AI音乐模型的”黑盒”,定位控制各类音乐属性的独立”开关”,让用户像调节音响旋钮一样,对速度、情绪、音色等维度进行精准、解耦的细粒度控制。
- Qwen3.5模型使用入口,开源版本Qwen3.5-397B-A17B采用创新混合架构
Qwen3.5通过早期文本-视觉融合、M-RoPE及3D位置编码技术,统一支持文本、图像、视频多任务处理,语言覆盖从119种扩展至201种。权威评测中表现顶尖:MMLU-Pro得分87.8超越GPT-5.2,GPQA得分88.4高于Claude 4.5,IFBench指令遵循评分76.5刷新行业纪录。
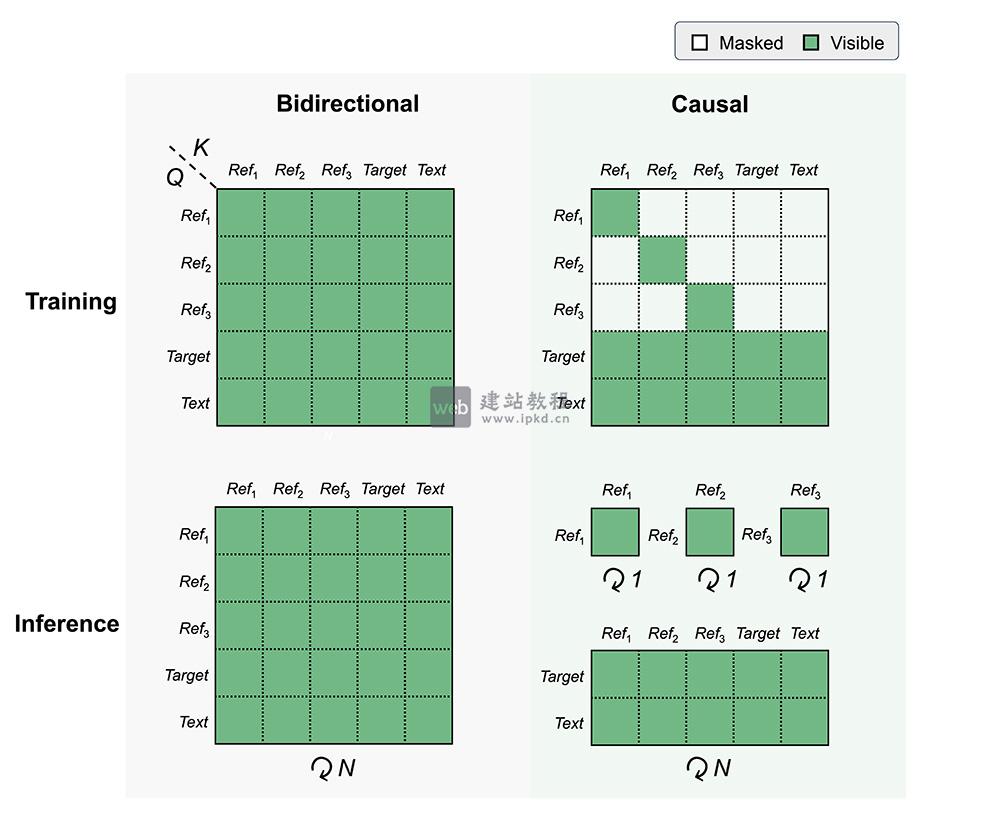
- Qwen-Image-Edit-Causal模型使用入口,Light AI优化版图像编辑模型
Qwen-Image-Edit-Causal V1.0是Light AI针对Qwen-Image-Edit-2511推出的关键优化版本,核心突破在于引入分块因果注意力机制,实现“编辑质量不打折、推理速度大幅提升”的双重优势,既延续了前代模型的精准编辑能力,又解决了图像编辑中“耗时久、效率低”的核心痛点,适配更多实时编辑与批量处理场景。
- Kimi Claw模型使用入口,月之暗面Moonshot AI云端AI智能体服务
Kimi Claw是月之暗面推出的云端AI智能体服务,核心是Kimi K2.5大模型与开源AI Agent平台OpenClaw的深度集成方案,堪称当前性价比顶尖的“模型+Agent”组合。它既保留OpenClaw的自动化助手核心能力,又无需用户进行本地部署与维护——在Kimi平台几秒内即可完成部署。

- CoPAW官网使用入口,阿里云通义实验室个人智能体工作台,你的专属数字搭档
CoPaw是阿里云通义实验室重磅推出的个人智能体工作台,平台内置文档处理、新闻阅读、浏览器操作等多种基础能力(Skills),同时支持自定义Skill轻松扩展功能边界,无需修改底层代码。

- JoyAI-LLM-Flash模型使用入口,京东AI开源的最新大语言模型
JoyAI-LLM-Flash是京东在Hugging Face正式开源的最新大语言模型,该模型采用混合专家(MoE)架构,总参数达480亿,而每次推理仅激活30亿参数,既能保持强大的模型能力,又能显著降低计算开销。