AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- Gemini 3 Deep Think模型使用入口,Google DeepMind旗舰级科学推理模型
Gemini 3 Deep Think是Google DeepMind专为深度科研设计的推理模型,核心优势为奥赛金牌级科学推理、顶尖编程能力、工程迭代加速;性能上在ARC-AGI-2等核心基准大幅领先同类模型,已验证能识别人类评审遗漏的论文逻辑漏洞。

- GPT‑5.3‑Codex‑Spark模型使用入口,OpenAI首款实时编程轻量级模型
GPT-5.3-Codex-Spark是OpenAI首款实时编程轻量级模型,核心优势为1000 tokens/秒超高速推理、80%延迟降低、边输出边修改的即时协作体验;核心应用于即时代码调试、界面迭代、代码审查、编程学习、原型验证等需要快速响应的编码场景,已向 ChatGPT Pro用户开放。

- MiniMax M2.5官网使用入口,大规模强化学习训练实现能力全面升级
MiniMax M2.5是全维度升级的前沿大模型,在编程、搜索、办公等核心生产场景达SOTA水平,推理速度提升37%,成本仅为同类模型1/10~1/20;技术底层依托数十万个真实环境的 RL 训练、自研Forge框架实现40倍训练加速,迭代速度行业领跑。

- MiniCPM-SALA模型使用入口,面壁智能开源的9B量级端侧大模型
MiniCPM-SALA是9B端侧大模型,核心突破为消费级显卡支持百万级上下文推理,兼具低显存、快推理的优势;技术核心是SALA混合注意力、HyPE混合位置编码,兼顾长文本效率与短文本性能;核心适配个人智能助手、端侧知识库、车载系统、科研文献分析等本地化长文本场景。
- GLM-5模型官网使用入口,智谱AI推出的新一代旗舰级开源大模型
GLM-5是智谱AI旗舰开源大模型,744B参数规模+28.5T预训练数据,性能位列全球第四、开源第一,适配国产算力;核心优势为复杂系统工程交付、长程Agent任务执行、多工具协同,技术层面依托Slime异步RL、稀疏注意力等创新降本增效;核心应用于系统开发、遗留系统重构、智能运维、数字助手、经营决策优化等场景。

- Ming‑Flash‑Omni 2.0模型使用入口,蚂蚁集团开源的全模态大模型
Ming-flash-omni-2.0是蚂蚁集团开源的SOTA全模态大模型,MoE架构兼顾性能与效率,核心实现图像/视频/音频/文本的统一理解与生成;核心适配智能教育、内容创作、文博数字化、实时交互娱乐、智能图像处理等场景。

- SoulX-Singer模型官网使用入口,工业级零样本歌声合成模型
SoulX-Singer是工业级零样本歌声合成模型,核心优势为零样本克隆、双模式控制、跨语言合成,性能领先开源方案;技术层面依托Flow Matching架构、显式多模态对齐等创新,兼顾生成效率与自然度;核心适配虚拟歌手打造、音乐二创、专业创作辅助、个性化娱乐等场景。

- 讯飞星火X2模型官网入口,科大讯飞依托全国产算力训练的新一代大模型
讯飞星火X2是科大讯飞依托全国产算力训练的新一代大模型,模型实现单台昇腾服务器部署,推理性能较上一代X1.5提升50%;业界首发错因贯穿的个性化学习能力,深度赋能教育、医疗、汽车等多行业,模糊意图理解从“不可用”跃升至“基本好用”。
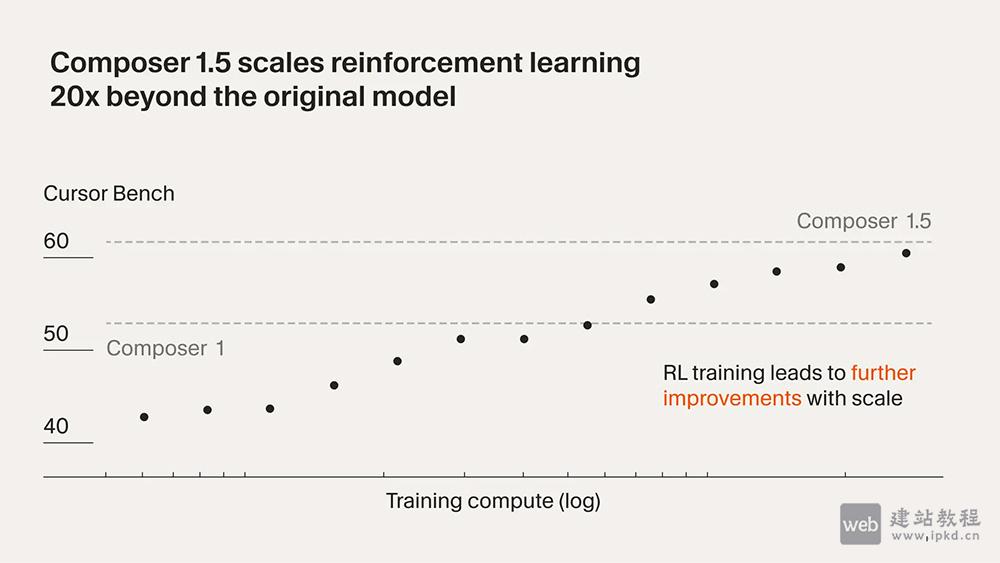
- Composer 1.5模型使用入口,Cursor自研的AI编程模型
Composer 1.5是Cursor自研的AI编程模型,该模型具备强大的自我总结能力,可在上下文耗尽时自动压缩状态、持续探索解决方案;在内部基准测试中,其性能已全面超越前代,尤其在各类挑战性编码任务上的提升尤为显著,大幅优化编程效率与精准度。
- Seedance 2.0 Pro官网使用入口,字节跳动自研、基于即梦AI模型的AI视频生成平台
Seedance 2.0 Pro是由字节跳动自研、基于Jimeng AI模型的AI视频生成平台,依托字节跳动领先技术,打造专业级AI视频创作能力。平台核心优势为流畅相机运动、时间一致性、复杂场景深度理解与高效视频生成。
- Lesson Plan Generator官网使用入口,内置CCSS、NGSS及各州课程标准数据库
LessonPlanGenerator是一款由教育工作者开发的AI教案生成工具,内置CCSS、NGSS及各州课程标准数据库,可自动生成差异化教案,大幅节省教师备课时间,提升备课效率与教案质量。

- RynnBrain官网使用入口,阿里达摩院开源的具身智能大脑基础模型
RynnBrain是阿里巴巴达摩院推出的开源具身智能大脑基础模型,基于Qwen3-VL训练并采用自研RynnScale架构,首次赋予机器人时空记忆与物理空间推理能力。

- HY-1.8B-2Bit模型使用入口,腾讯混元产业级2Bit端侧大模型
HY-1.8B-2Bit是腾讯混元推出的首个产业级2Bit端侧大模型,基于1.8B基座通过量化感知训练(QAT)极致压缩而成。模型体积仅300MB,内存占用约600MB,等效参数量0.3B,却能保留原模型完整推理能力,生成速度提升2–3倍,已深度适配Arm SME2等移动平台。
- Seedream 4.5模型使用入口,火山方舟、豆包、即梦AI等平台直接体验
Seedream 4.5是字节跳动专为商业生产力打造的新一代AI图像生成模型,在主体一致性、指令遵循、空间逻辑与美学质感上全面升级,重点强化多图自然融合能力,可无缝支撑广告、电商、影视、教育、数字娱乐等核心场景。
- Seedream 4.0模型使用入口,通过即梦AI、豆包直接使用
Seedream 4.0是字节跳动全新一代生成与编辑一体化AI图像模型,支持文本/图像组合输入、多图融合、自由风格迁移,分辨率最高可达4K超高清,推理速度较上一代提升10倍以上。关键指标位居行业前列,个人用户可通过火山方舟体验中心、即梦AI、豆包直接使用。