AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- Project Genie官网:谷歌DeepMind推出的实验性AI世界模型原型
Project Genie平台支持第一、第三人称双视角,用户可通过步行、骑行、飞行、驾驶等方式探索虚拟世界,系统会跟随用户移动即时生成前方场景,带来沉浸式的虚拟探索体验。

- TTT-Discover:斯坦福&英伟达联合推出,赋能AI科学发现的全新范式
TTT-Discover是斯坦福大学、英伟达等顶尖机构联合研发的AI科学发现核心方法,打破传统模型测试阶段仅冻结权重做搜索的模式,创新性在测试阶段对模型开展强化学习训练,通过熵目标函数优化最大奖励,结合PUCT启发的状态重用机制,让模型从具体问题的尝试与探索中实现实时动态学习。

- MOVA模型:中国首个高性能开源音视频端到端生成模型
MOVA是上海创智学院OpenMOSS团队与模思智能联合推出的中国首个高性能开源音视频端到端生成模型。拥有320亿参数,可同步生成长达8秒、720p分辨率的视频与配套音频,在电影级口型同步、环境音效契合度上表现卓越。
- LingBot-World官网:蚂蚁灵波科技开源的交互式世界模型
模型支持近10分钟连续稳定生成,响应速度达16 FPS且端到端延迟控制在1秒内,还具备Zero-shot场景泛化能力,有效解决真实世界训练数据稀缺、成本高昂的痛点,可广泛应用于机器人训练、自动驾驶仿真、游戏开发等领域。
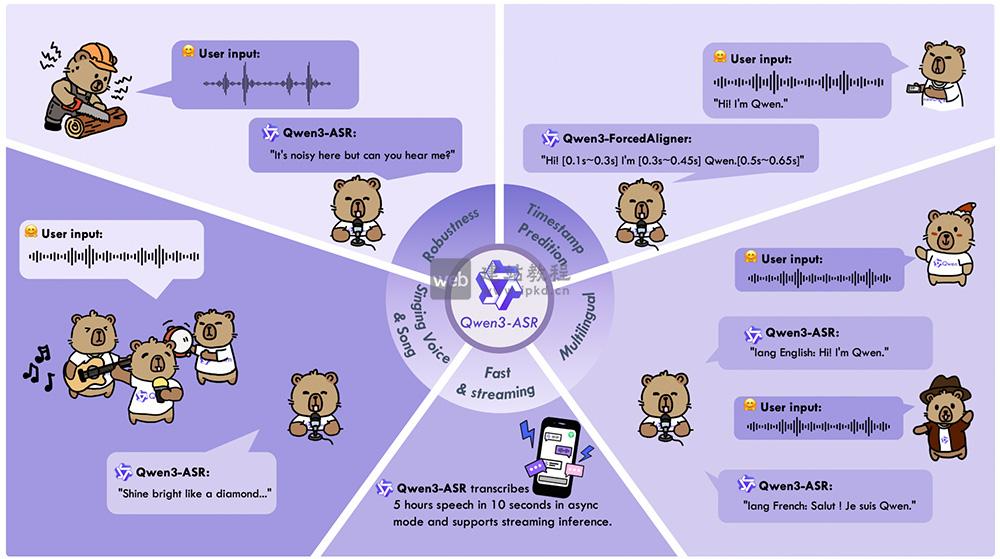
- Qwen3-ASR:阿里云通义千问团队开源的语音识别模型系列
Qwen3-ASR是阿里云通义千问团队开源的语音识别模型系列,模型支持52个语种与方言识别、流式/非流式一体化推理,在强噪声、快语速、歌唱等复杂场景下表现稳定鲁棒——1.7B模型在中英文及方言识别领域达开源SOTA水平,0.6B模型可支持128并发、2000倍吞吐,10秒即可处理5小时音频,兼顾精度与效率需求。
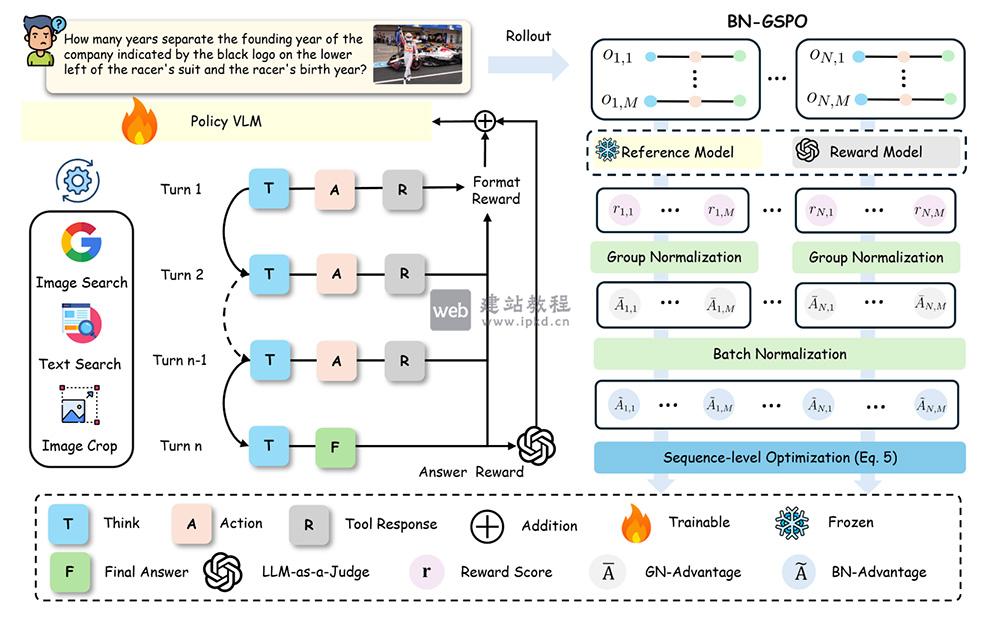
- SenseNova-MARS:商汤科技开源的AI多模态自主推理模型
SenseNova-MARS模型可像智能体一样自主规划任务步骤,灵活调用图像裁剪、文本搜索、图像搜索三大工具,无需人工干预即可完成复杂多跳推理。

- Actionbook:一个专为大语言模型的AI智能体网页操作辅助工具
Actionbook是一个专为大语言模型(LLMs)提供实时最新的DOM结构与专业行动指南,核心解决智能体操作网站时难以处理动态页面、复杂DOM树、流式内容等行业痛点。
- SkyReels-V3:昆仑万维开源多模态视频生成模型,专业级全模态视频创作
模型支持静态图像转动态影像、智能视频时长延长、电影级专业转场,更能实现数字人音视频精准同步,为创作者打造从短片段到长叙事的一站式视频生成解决方案,全方位适配商业创作、内容生产、行业应用等多元视频需求。

- LongCat-Flash-Lite官网:美团新一代高效大语言模型
LongCat-Flash-Lite是美团重磅推出的新一代高效大语言模型,凭借创新MoE+N元语法嵌入混合架构实现技术突破,总参数量达685亿,推理时仅激活29~45亿参数,完美平衡模型能力与运行效率。
- Mureka V8:昆仑万维旗舰级AI音乐大模型,由模型自动生成完整歌曲
Mureka V8是昆仑万维重磅推出的新一代AI音乐大模型,深度依托MusiCoT音乐思维链技术架构,实现从传统声音拼接向类人创作逻辑的核心跨越。模型在旋律完整性、人声表现力、编曲层次感、音质空间感四大核心维度完成全面升级。

- MiniMax-M2-her:MiniMax推出专为深度AI陪伴场景打造的专属角色扮演大模型
MiniMax-M2-her是MiniMax专为深度AI陪伴场景打造的专属角色扮演大模型,作为星野/Talkie的核心底层模型,凭借世界构建、故事推进、偏好感知三大核心能力,精准破解长对话中角色崩坏、剧情重复、体验衰减等行业痛点。

- MiniMax Music 2.5:MiniMax推出的新一代AI音乐创作模型
MiniMax Music 2.5模型支持14种音乐结构标签精准调控,创作者可像专业编曲人一样设计音乐情绪曲线;同时针对华语流行深度优化,实现清晰咬字、自然人声演绎、风格化智能混音,搭配100+乐器适配能力,达到录音室级制作水准,全方位满足多元音乐创作需求。

- NVIDIA Earth-2:全球首套完全开源的AI气象预测模型
NVIDIA Earth-2是英伟达推出的全球首套完全开源AI气象预测模型家族,依托Atlas、StormScope、HealDA三大核心架构,分别实现15天全球中期预报、0-6小时公里级临近预报、秒级初始条件生成。
- Lucy 2.0:Decart AI实时世界转换模型,重构高保真视觉编辑体验
Lucy 2.0能有效校正长期运行中的质量漂移问题,实现数小时不间断的连贯生成。针对AWS Trainium3硬件深度优化后,模型可广泛应用于实时角色替换、虚拟试装等视觉特效场景,同时为机器人训练提供物理一致的实时数据增强与模拟环境。
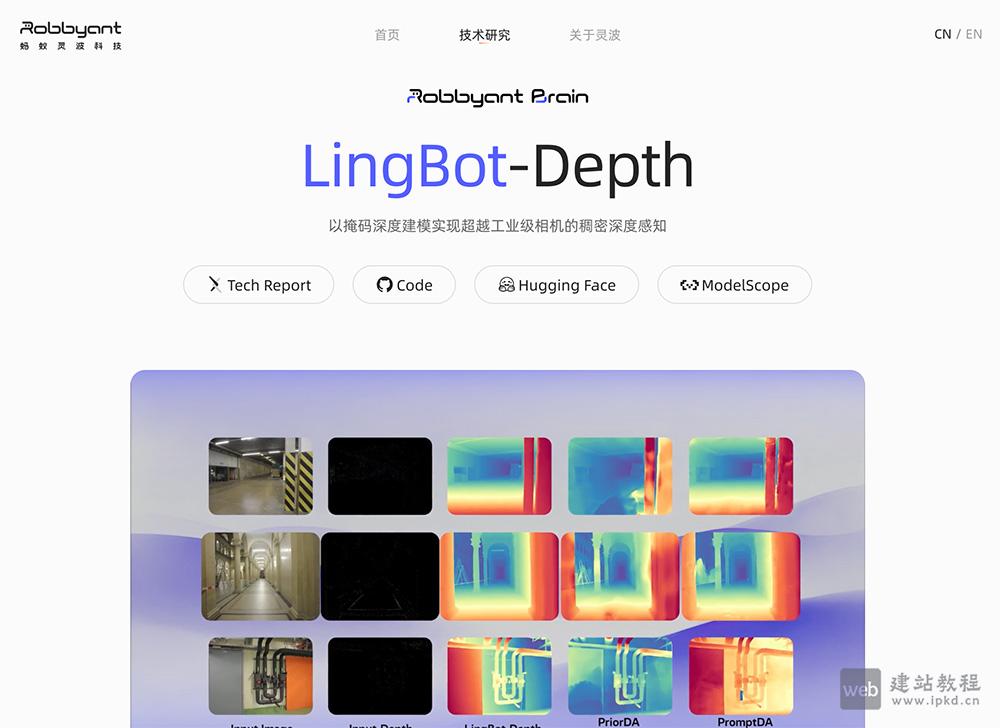
- LingBot-Depth:专为攻克机器人在透明、反光物体场景的AI模型
LingBot-Depth是蚂蚁灵波科技开源的高精度空间感知模型,该模型在深度补全、单目深度估计及机器人抓取等核心任务中表现卓越,可助力机器人精准理解三维环境,加速具身智能技术的落地应用。