AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
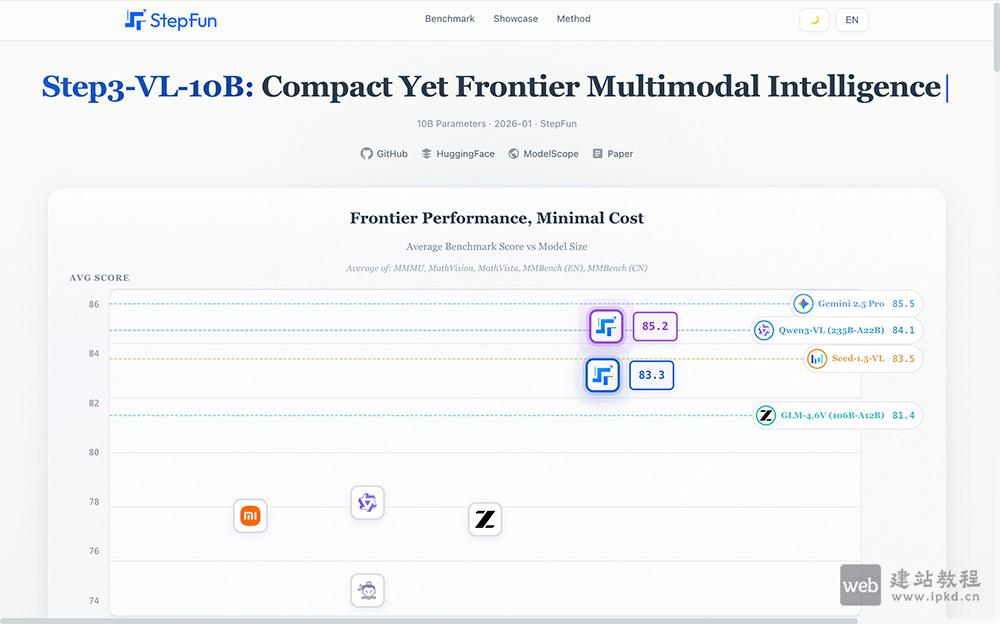
- Step3-VL-10B:10B参数开源多模态模型,以轻量架构比肩200B级性能
Step3-VL-10B是阶跃星辰推出的轻量级开源多模态模型,仅搭载10B参数,却能在视觉感知、逻辑推理、数学竞赛及通用对话等核心任务中,达到200B大参数模型的性能水准。

- NovaSR:一款极致轻量化的开源音频超分辨率模型
NovaSR是一款极致轻量化的开源音频超分辨率模型,仅52KB大小即可实现核心音质升级——将16kHz低采样率音频精准提升至48kHz高采样率音频。

- VerseCrafter:复旦联合腾讯PCG ARC Lab等机构研发的动态真实视频世界模型
VerseCrafter是复旦大学联合腾讯PCG ARC Lab等机构研发的动态真实视频世界模型,该模型基于大规模真实世界数据集VerseControl4D完成训练,可高效处理复杂动态场景,生成的视频内容具备极强的时空一致性。

- x-Algorithm:马斯克团队开源的 x 平台个性化推荐算法
x-Algorithm是马斯克团队开源的平台个性化推荐算法,是支撑“为你”信息流的核心系统。该算法创新性整合用户关注账号的帖子(In-Network)与机器学习检索的全球内容(Out-of-Network),依托基于Grok的Transfo

- QwenLong-L1.5:阿里通义实验室推出的长文本推理大语言模型
QwenLong-L1.5是阿里通义实验室推出的长文本推理专用大语言模型,基于Qwen3-30B-A3B架构打造。通过系统化后训练方案,结合高质量数据合成管线、稳定强化学习方法与突破物理窗口限制的记忆管理框架。

- MiniMax M2.1:MiniMax推出新一代多语言编程与综合智能AI模型
MiniMax M2.1是MiniMax推出的新一代多语言编程AI模型。相较于前代MiniMax M2,该模型系统性强化Rust、Java、Golang等主流编程语言的支持能力,覆盖从底层系统开发到上层应用开发的全链路场景;同时增强Web与

- Seed Prover 1.5:字节跳动Seed团队研发的形式化数学推理模型
Seed Prover 1.5是字节跳动Seed团队研发的新一代形式化数学推理模型,该模型创新性采用Agentic Prover架构,依托大规模强化学习(Agentic RL)完成训练,实现数学推理能力与效率的双重跃升。

- GPT-5.2-Codex:OpenAI推出的智能体编程专用模型
GPT-5.2-Codex是OpenAI推出的智能体编程专用模型,专为复杂软件工程与防御性网络安全任务打造。该模型基于GPT-5.2架构升级迭代,强化指令遵循与长语境理解能力,在代码重构、跨环境迁移等大型工程变更任务中表现突出。

- Gemini 3 Flash:谷歌推出基于Gemini 3架构的高速低成本智能模型
Gemini 3 Flash是谷歌推出的高速低成本前沿智能模型,基于Gemini 3架构迭代开发,兼具强劲推理性能与多模态理解能力。在多项权威基准测试中,该模型表现比肩甚至超越Gemini 3 Pro、GPT-5.2等更大规模模型。

- Seedance 1.5 Pro:字节团队研发的原生音画同步多模态视频生成模型
Seedance 1.5 Pro是字节跳动Seed团队研发的原生音画同步多模态视频生成模型,支持通过文本指令生成高质量视频内容,覆盖多语言、多方言及多样人声与音效。

- DeepSeek-Math-V2:DeepSeek团队开源的自我验证型数学推理模型
DeepSeek-Math-V2是DeepSeek团队推出的开源数学推理模型,模型聚焦答案正确性与推理过程严谨性,通过训练定理证明验证器与生成器,创新引入元验证机制,让模型能够像人类数学家一样审查证明逻辑、实现自我纠错。

- StepAudio R1:阶跃星辰团队研发的全球首个开源原生音频推理模型
StepAudio R1是阶跃星辰团队研发的全球首个开源原生音频推理模型,核心依托创新的模态锚定推理蒸馏(MGRD)框架,攻克传统音频模型在复杂推理任务中性能衰减的技术痛点,真正实现基于声学特征的深度推理。

- GELab-Zero:阶跃星辰开源的轻量化移动GUI Agent模型
GELab-Zero是阶跃星辰研发的开源GUI Agent模型,模型支持在消费级硬件上运行4B参数版本,兼顾低延迟响应与数据隐私保护;提供一键多终端部署能力,自动处理环境依赖与设备管理,兼容分布式任务编排及多模态Agent模式,可灵活应对复杂移动自动化任务。

- Vidi2:字节跳动多模态大语言模型,赋能视频理解与智能创作
Vidi2是字节跳动推出的专注于视频理解与创作的多模态大语言模型,模型可基于文本查询,精准识别视频对应时间戳并标记目标对象边界框,还创新引入VUE-STG、VUE-TR-V2两大基准测试,为STG能力评估提供更科学的标准。

- 可灵O1:可灵AI推出的全球首款统一多模态视频生成模型
可灵O1是可灵AI研发的全球首个统一多模态视频生成模型,模型支持图片、视频、文字等多模态输入,可一站式完成全能创作与编辑,精准解决视频生成中的主体一致性难题,解锁多元创意组合玩法。