AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。
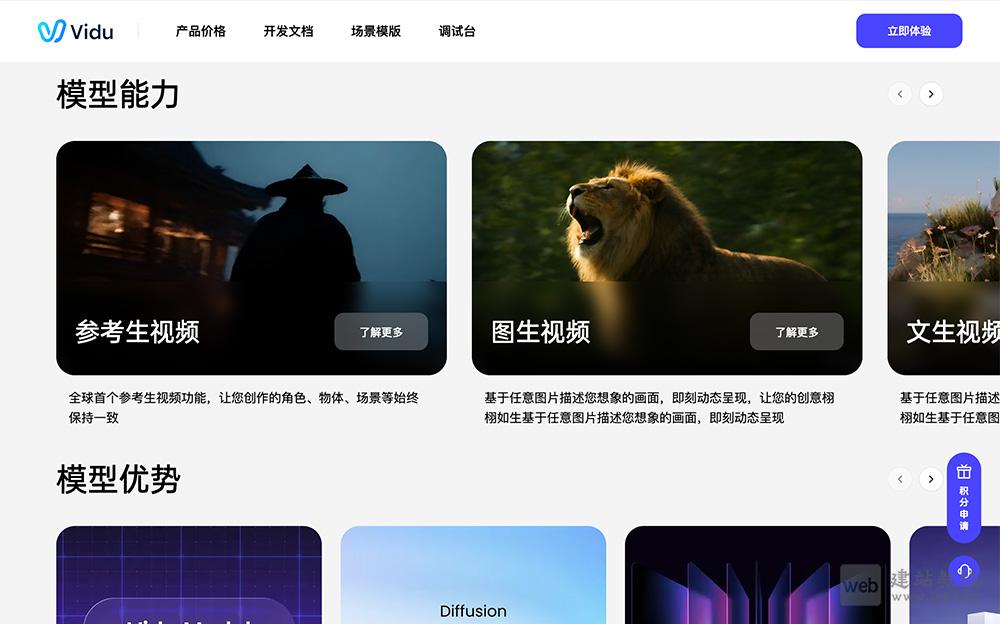
- Vidu Q2参考生Pro:一键复刻人物表情、复杂动作、特效画面等
Vidu Q2参考生Pro是全球首创的「万物可参考」生产级视频生成模型,创新性支持多模态素材输入,赋能创作者一键复刻人物表情、复杂动作、特效画面、场景氛围与纹理细节,实现视频内容的精细化编辑。
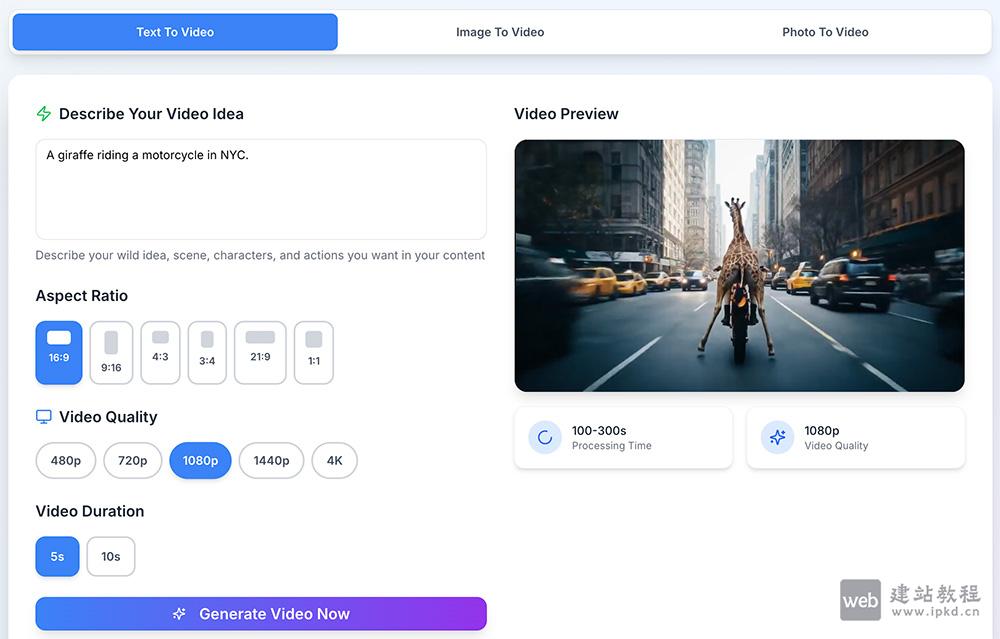
- VO4 AI Video:无需专业编辑技能,即可轻松将文本、图像转化为高质量视频内容
VO4 AI Video Generator是一款基于前沿AI技术打造的在线视频生成平台,无需专业编辑技能,即可轻松将文本、图像转化为高质量视频内容。
- DeepSeek-OCR 2:DeepSeek团队推出的第二代高性能OCR模型
DeepSeek-OCR 2是DeepSeek团队推出的第二代高性能光学字符识别模型,模型搭载因果流查询与双流注意力核心机制,可动态重排视觉Token,精准还原复杂文档的自然阅读逻辑。
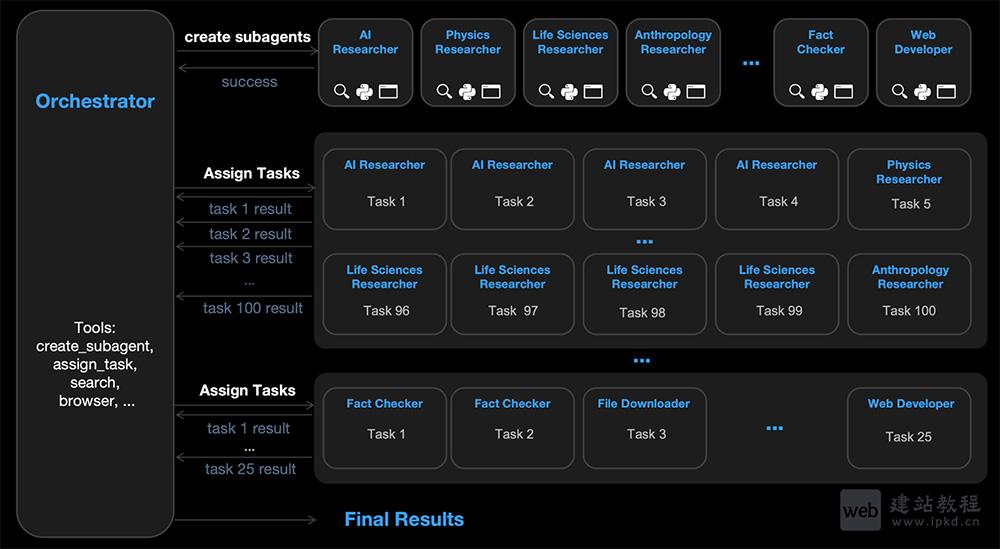
- Kimi K2.5:月之暗面Kimi开源的全新一代全能旗舰多模态大模型
Kimi K2.5是月之暗面开源的全新一代全能旗舰多模态大模型,基于约15T视觉与文本混合数据训练打造,兼具顶尖的代码生成、视觉理解能力,创新性支持自主Agent集群协作机制,可调度多达100个子Agent并行处理复杂任务,实现执行效率的量级提升。
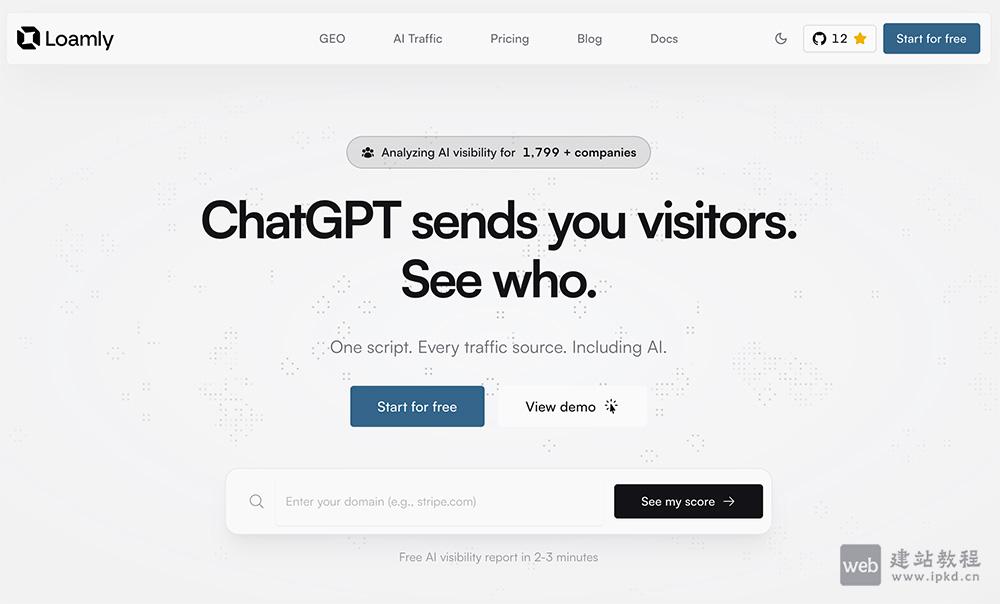
- Loamly:专为解决传统分析工具无法精准识别AI来源流量的分析平台
Loamly是一款开源网站流量分析平台,专注解决传统分析工具无法精准识别AI来源流量的行业痛点,助力企业清晰掌握生成式AI为业务带来的流量价值。
- SoraX:一款依托Sora 2核心技术打造的AI视频生成平台
SoraX平台支持文本、图像一键生成专业级高质量视频,兼具操作简易、性价比高的优势,还配备免费额度降低试用门槛,凭借强大的技术支撑与灵活的创作模式,成为快速产出优质视频内容的得力工具。
- WeryAI:整合Kling、Sora、Flux等模型于一体的AI创意创作平台
WeryAI是一款一体化AI创意创作平台,深度整合Kling、Google Veo、Sora、Flux等全球顶尖AI模型,打造 “一站式” 创作工作台。用户无需在多个平台间切换,即可畅享多类型 AI 创作服务。

- 白虎-VTouch:一个跨本体视触觉多模态的机器人操作数据集
白虎-VTouch是国家地方共建人形机器人创新中心联合纬钛机器人开源的全球首个最大规模跨本体视触觉多模态数据集,涵盖视触觉传感器数据、RGB-D数据、关节位姿数据等多维度信息,覆盖轮臂机器人、双足机器人等多种机器人本体构型,累计数据规模超6万分钟。

- TensorRT LLM:专为NVIDIA GPU量身打造的推理性能优化框架
TensorRT LLM是NVIDIA推出的大型语言模型(LLM)推理性能优化框架,专为NVIDIA GPU量身打造,基于PyTorch架构构建,提供简洁易用的Python API,可无缝适配从单GPU轻量部署到大规模分布式集群推理的全场景需求。
- Qwen3-Max-Thinking:阿里千问系列全新推出的旗舰级推理大模型
Qwen3-Max-Thinking模型大幅强化原生Agent能力,可自适应自主调用工具,输出更智能、流畅且精准的回答。目前开发者与普通用户可通过Qwen Chat、千问PC端及网页端免费体验,企业可通过阿里云百炼获取专属API服务,千问APP也即将完成新模型接入。
- Veo 3.2:一款增强型AI视频生成模型,高质量动态视频
Veo 3.2是一款增强型AI视频生成模型,该模型凭借角色与场景一致性、原生竖屏支持、4K超分等核心优势,大幅降低专业视频制作门槛,无论是业余爱好者还是专业创作者,都能高效实现创意落地。

- vLLM:加州大学伯克利分校开源的高性能大语言模型推理与部署框架
vLLM是加州大学伯克利分校 Sky Computing Lab 开源的高性能大语言模型(LLM)推理与部署框架,核心目标是为用户提供低延迟、高吞吐量、低成本的大模型服务。

- SGLang:一款面向大语言模型与多模态模型的开源高性能推理框架
SGLang是一款面向大语言模型与多模态模型的开源高性能推理框架,该框架兼容Llama、Qwen、DeepSeek等主流模型及NVIDIA、AMD GPU、CPU、TPU等多类硬件平台,依托先进的推理优化技术与活跃社区支持,助力大模型高效落地于各类实际应用场景。
- 混元图像3.0图生图模型:腾讯推出的先进图像生成与编辑大模型
混元图像3.0图生图模型是腾讯推出的先进图像生成与编辑大模型,基于80B参数混合专家(MoE)架构打造,具备深度理解输入图像与文本编辑指令的能力,可快速生成高质量、真实感强且情绪表现力丰富的图像内容。

- OpenJudge:一款面向AI应用全生命周期的开源评测框架
OpenJudge提供从基础性能评测到定制化场景评测的完整解决方案,支持多业务场景覆盖与灵活集成,助力AI应用持续优化升级。