AI项目和框架

- [推荐] 豆包网页版:支持AI聊天,AI图片生成,AI漫画生成,AI写作等
字节跳动开发的一款多功能人工智能工具,基于云雀模型(豆包大模型)构建。它不仅是一个AI聊天机器人,还具备多种功能,包括写作助手、英语学习助手、音乐生成、编程助理等。

- VoxCPM:0.5B轻量语音生成模型,重塑高保真实时语音合成体验
VoxCPM支持零样本声音克隆,仅需一段参考音频,即可精准复刻说话者的音色、口音、情感语调等细微特征,生成高度逼真的个性化语音。其推理效率同样表现卓越,在NVIDIA RTX 4090 GPU上实时因子(RTF)低至0.17,完美满足实时交互场景需求。

- DeepSeek-R1-Safe:浙大与华为联合研发的安全专项大模型
DeepSeek-R1-Safe是浙江大学网络空间安全学院与华为联合研发的安全专项大模型,基于DeepSeek系列模型迭代升级,深度适配华为昇腾芯片与MindSpeedLLM框架,构建起“安全语料构建—安全监督训练—强化学习优化”的全链路技术体系。

- Granite-Docling-258M:IBM轻量级视觉语言模型
Granite-Docling-258M模型支持阿拉伯语、中文、日语等多语言处理,并创新性采用DocTags格式精准描述文档结构,搭配与Docling库的无缝集成能力,赋予用户强大的定制化空间与错误处理机制,成为企业级文档智能化升级的高效利器。

- LongCat-Flash-Thinking:美团 5600 亿参数 MoE 推理模型
LongCat-Flash-Thinking-2601专为智能体设计,创新性引入“重度思考模式”,通过并行推理与迭代总结机制,大幅提升多步骤、高复杂度开放式任务的处理能力;同时经过系统性抗噪训练,模型在嘈杂的真实业务环境中具备超强鲁棒性,多项Agent基准测试成绩跻身业界顶尖水平。

- DeepSeek-V3.1-Terminus:DeepSeek团队推出的新一代人工智能语言模型
DeepSeek-V3.1-Terminus是DeepSeek团队推出的新一代人工智能语言模型,作为DeepSeek-V3.1的重磅升级版本,该模型聚焦语言一致性优化与Agent能力强化两大核心方向,精准解决中英文混杂、异常字符干扰等行业痛点,实现输出内容的规范性与稳定性双重跃升。

- Qwen3-Omni:阿里通义团队推出业界首个原生端到端全模态AI模型
Qwen3-Omni支持119种语言文本交互、19种语音理解语言及10种语音生成语言,轻松覆盖全球主流语种,满足跨地域业务需求。响应速度更实现突破性优化,纯模型端到端音频对话延迟低至211ms,视频对话延迟低至507ms,搭配长达30分钟的长音频理解能力,为实时交互场景提供流畅体验。

- Qwen3-TTS-Flash:开源语音合成模型,49种音色+10种语言+9种方言
Qwen3-TTS-Flash在语音自然度上实现跨越式升级。通过智能语速韵律调节技术,合成语音能够精准还原真人表达的情绪起伏与语言节奏——无论是娓娓道来的知识讲解,还是情绪饱满的剧情配音,都能传递出细腻的“人味”,彻底告别机械感。

- Qianfan-VL:百度智能云千帆企业级视觉理解大模型,赋能多模态场景落地
Qianfan-VL是百度智能云千帆面向企业级多模态应用场景打造的核心视觉理解大模型,提供3B、8B、70B三种差异化尺寸版本,兼顾通用能力与垂直场景专项优势,尤其在OCR识别、教育解题等领域经过深度强化。
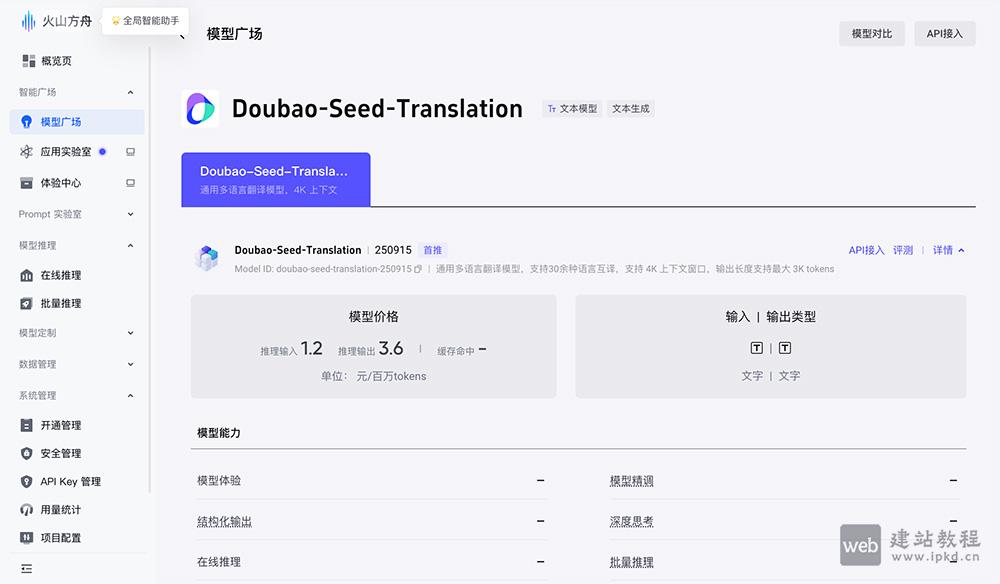
- Doubao-Seed-Translation:字节跳动多语言翻译模型,重塑跨语言沟通新体验
Doubao-Seed-Translation是字节跳动团队研发的先进多语言翻译模型,支持28种语言双向互译,覆盖中英、日韩、德法等主流语种,凭借卓越的翻译性能,成为跨语言沟通的高效助手。

- Qwen3Guard:通义千问首款安全护栏模型,筑牢AI安全防护模型
Qwen3Guard的项目地址 项目官网:
- Qwen3-Max:阿里万亿参数大模型,刷新通用AI能力新高度
最新推出的Qwen3-Max Thinking是阿里的推理版AI模型,基于万亿参数的MoE架构,专门用在复杂问题的推理和思考。Qwen3-Max Thinking在数学竞赛、代码挑战等任务中表现优异,部分成绩超越国际主流模型如Claude Opus 4。
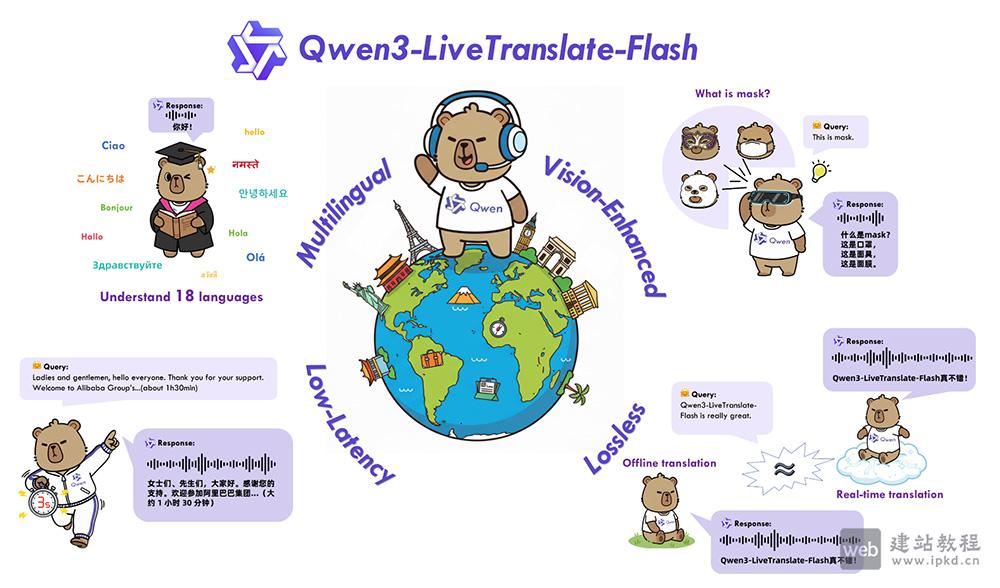
- Qwen3-LiveTranslate:阿里通义多语言实时音视频同传模型
Qwen3-LiveTranslate是阿里通义团队研发的大语言模型驱动型多语言实时音视频同传系统,支持18种主流语言及多地方言的精准翻译,创新性融合视觉增强技术,通过捕捉口型、动作等多模态信息,大幅提升复杂场景下的翻译准确性。

- 通义万相2.6:阿里云推出的最新一代AI视频与图像生成模型
通义万相2.6是阿里云推出的最新一代AI视频与图像生成模型,于2026年1月正式发布。作为通义万相模型家族的最新版本,它在视频生成和图像创作方面实现了重大突破,是国内首个支持角色扮演功能的视频模型。
- Wan2.5:阿里多模态生成模型重磅升级,解锁音画同步创作新体验
Wan2.5-Preview是阿里巴巴推出的新一代多模态生成模型,集成文生视频、图生视频、文生图、图像编辑四大核心功能,突破性实现音画同步的视频生成能力,支持1080P高清分辨率、24fps流畅帧率创作。

- LucaVirus:阿里云重磅发布 核酸-蛋白质统一语言模型
LucaVirus是阿里云LucaGroup潜心研发的全球首款专为病毒领域打造的核酸-蛋白质统一语言模型,依托254亿个核苷酸与氨基酸标记的海量数据完成训练,数据覆盖几乎所有已知病毒种类。